-
4장 말 잘 듣는 모델 만들기 4.1 코딩 테스트 통과하기LLM/LLM을 활용한 실전 AI 애플리케이션 개발 2025. 1. 26. 17:44
목차
GPT3 -> ChatGPT
1. 네이버 지식인처럼 요청/답변 형식으로 된 지시 데이터셋(instruction dataset)을 통해 사용자 요청에 응답할 수 있도록 학습시켰다.
2. 사용자가 더 좋아하고, 더 도움되는 답변을 생성할 수 있도록 추가 학습을 시켰다. 이를 선호(preference)를 학습이라 한다
가상의 코딩 테스트 서비스 : 엔지니어스
코딩테스트를 통해이를 해본다
사람들이 더 선호하는 답변 생성하도록 모델을 조정하는 방법
강화 학습( reinforcement learning)
근접 정책 최적화 (PPO, proximal policy optimization)
- 하이퍼 파라미터에 민감하고, 학습이 불안정해, 좌절 많이 함
지도 미세 조정 (supervised fine-tuning)
강화학습을 사용해 사람의 선호를 학습 시키는 RLHF(Reinforcement Learning from human feedback)
기각 샘플링 (rejective sampling) : 강화학습을 하지 않고 선호를 학습시키는
직접 선호 최적화 (DPO, Direct preference optimazation)
4.1 코딩 테스트 통과하기: 사전 학습과 지도 미세 조정
4.1.1. 코딩 개념 익히기 : LLM 의 사전 학습
코딩 테스트 위해 공부 하는 과정 예
01. Python programing 공부
02. 추천서 클론 코딩(clon coding) 공부
03. 자료구조와 알고리즘 공부

4.3 최고의 프로그래밍 언어 답변 예
파이썬 30%
자바 15%
영어 3%
산 0.7%

4.1.2 연습문제 풀어보기: 지도 미세 조정
사전 학습이 되었다면, 다음 과정은,
코딩 테스트 연습 문제 풀어보는 것
간단 예제 풀기
자주 나오는 문제와 그 정답 코드로 학습
패턴 : 문제 상황 설명, 필요한 코드 설명 - 예시 케이스
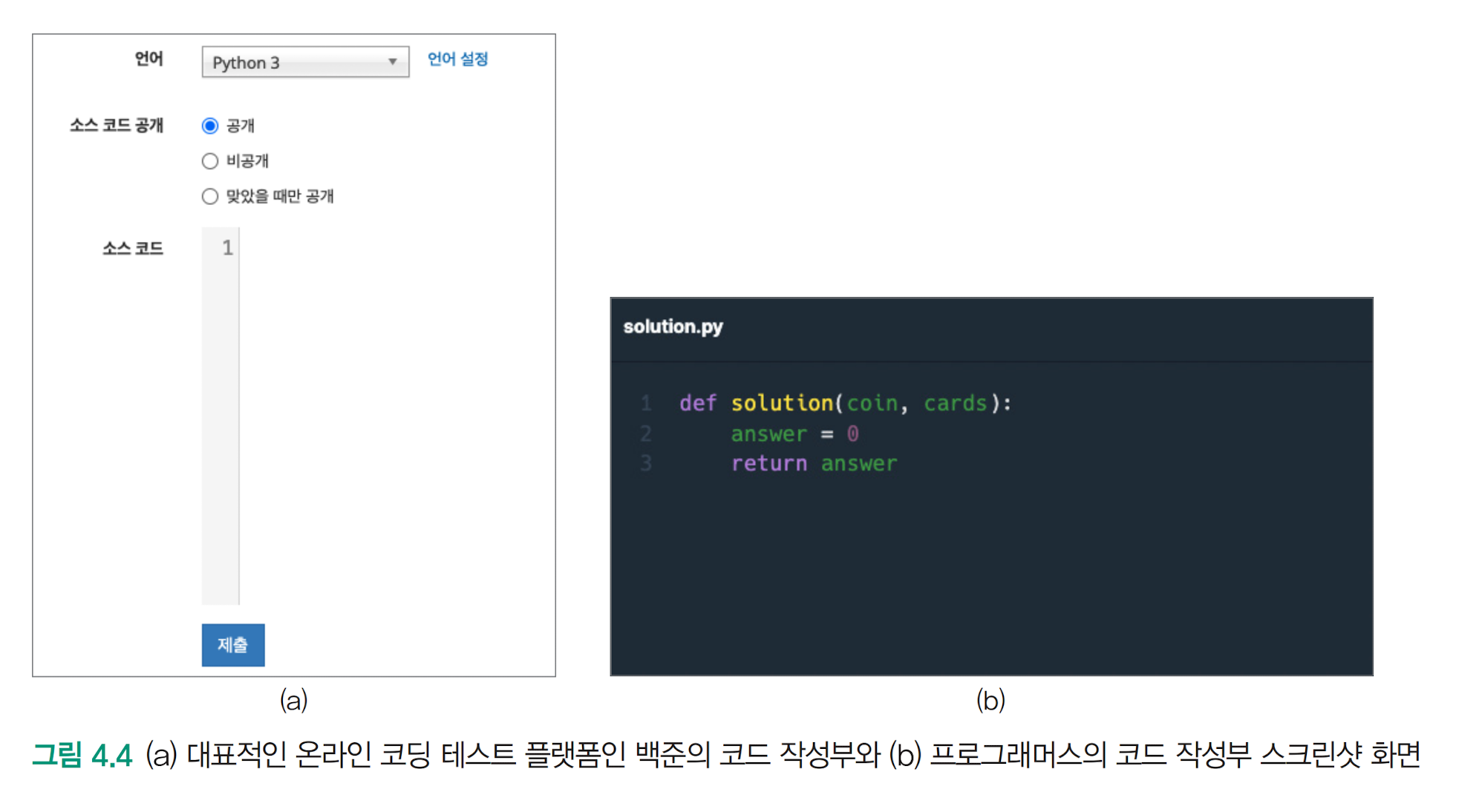
지도 미세 조정(Supervised fine-tuning) 에서 지도(Supervised)란 학습 데이터에 정답이 포함되어 있다는 의미다
지도 미세 조정을 통해 LLM 은 사용자의 요청에 맞춰 응답하도록 학습하는데, 이를 정렬 Alignment 라고 한다.
사람의 요청과 LLM 의 응답이 정렬되도록 한다는 의미다
지시 데이터셋(instruction dataset) 사용자의 지시에 맞춰 응답한 데이터셋
딥러닝 모델은 기본적으로 학습 데이터에 있는 행동을 배우기 때문에,
학습 데이터의 요청에 응답하는 데이터가 적다면 그 행동은 잘 배우지 못한다.
opeeAI는 데이터 labeler 를 고용해 13,000개가 넘는 지시 데이터셋을 구축해 모델을 학습시켰다.
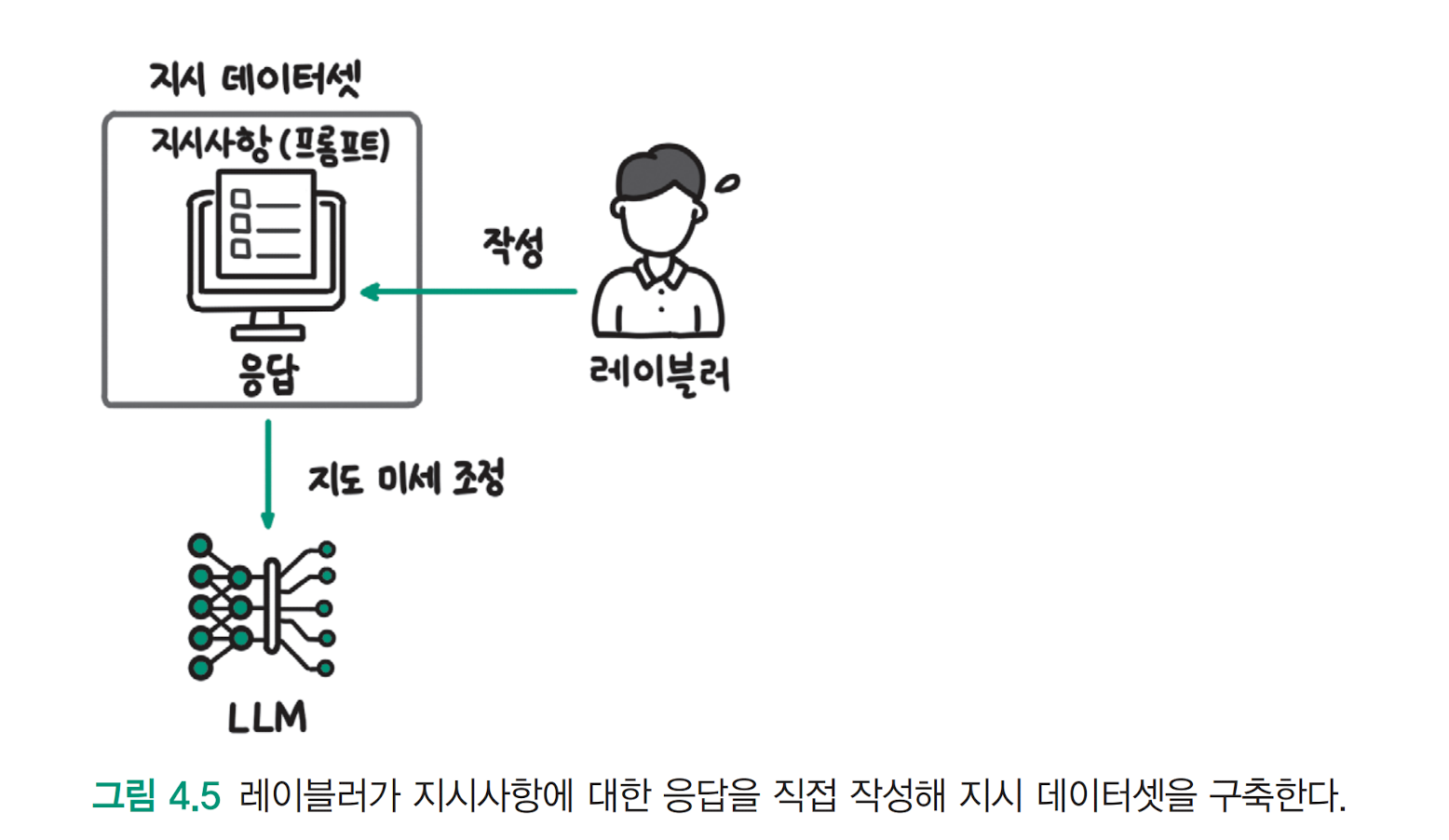
LLama 모델을 추가 학습한 알파카(Alpaca)의 데이터셋
지시사항(instruction)은 사용자의 요구사항을 표현한 문장이다.
1) instruction
create a classification task by clustering the given list of item ( 분류하세요 )
2) input 에는 답변을 하는 데 필요한 데이터가 들어간다
Apples, orange, banana, strawberries, pineapples
3) output 에는 지시사항과 입력을 바닽으로 한 정답 응답이다.
Class 1: Apples, Oranges
Class 2: Bananas, Strawberries
Class 3 : Pineapples


예제4.2 Template Example
Instruction
Input
Response

huggingface dataset url : https://huggingface.co/datasets/tatsu-lab/alpaca/viewer/default/train?row=5
지도 미세 조정도 다음 단어를 예측하는 인과적(일상적) 언어 모델링(Casual language modeling)을 사용한다
즉, LLM과 학습 방식은 같지만, 데이터셋에만 차이가 있다
4.1.3 좋은 지시 데이터셋을 갖춰야 할 조건
조건 예 : 데이터의 양, 품질, 질문의 형식, 답변의 형식
Meta
Less is More for Alignment (정렬, 더 적은것이 낫다, 2023)
파라미터 650억 개인 LLama 모델
정렬은 1,000 개 정도의 지시 데이터셋만 사용
또, 지시 데이터셋에서 지시사항이 다양한 형태로 되어 있고, 응답 데이터의 품질이 높을수록 정렬한 모델의 답변 품질이 높아진다
주 데이터 셋 : wikihow, stack exchange
stack exchange 는 질문의 형식은 다양하지만, 답변의 퀄리티가 낮아 -> 퀄리티 높은 답변만 선별하여 지시데이터 셋 구성
메타는 피상적인(깊이없는) 정렬 가설 Superficial Alignment Hopthesis 을 주장
: 사전 학습 단계에서 대부분 학습, 정렬은 적은 데이터로
Microsoft
Textbooks Are All You Need( 텍스트북이면 충분하다 )
지시 데이터셋의 품질을 높이면 더 작은 데이터셋과 더 작은 모델로도 높은 성능을 달성할 수 있다
파이썬 코드 생성 모델Phi, 파라미터가 13억 개인 작은 모델이지만 훌륭한 성능
Phi, 파라미터 13억개 : https://ollama.com/library/phi4
wizardCoder 160억개 : https://ollama.com/library/wizardcoder
공개된 코드 데이터셋을 그대로 사용하지 않고, 선별한 이유
* 외부 모듈이나 파일을 사용하기 때문에 하나의 코드 파일 자체에서 의미를 이해하기 어려움
* 많은 파일이 의미 있는 연산보다는 보일러플레이트boilerplate 코드나 설정파일
* 복잡하거나 제대로 문서화되지 않은 함수들은 의미를 파악하기 어려움
* 특정 주제나 사례에 관련된 코드가 많아, 불균형한 데이터셋 분포

(a) 교육적 가치 높음
함수명이 의미있게 작성
doc 도 잘 작성
(b) 교육적 가치 낮음
default(init) 설정용도
doc string 내용을 바탕으로 코드를 구현하는 예
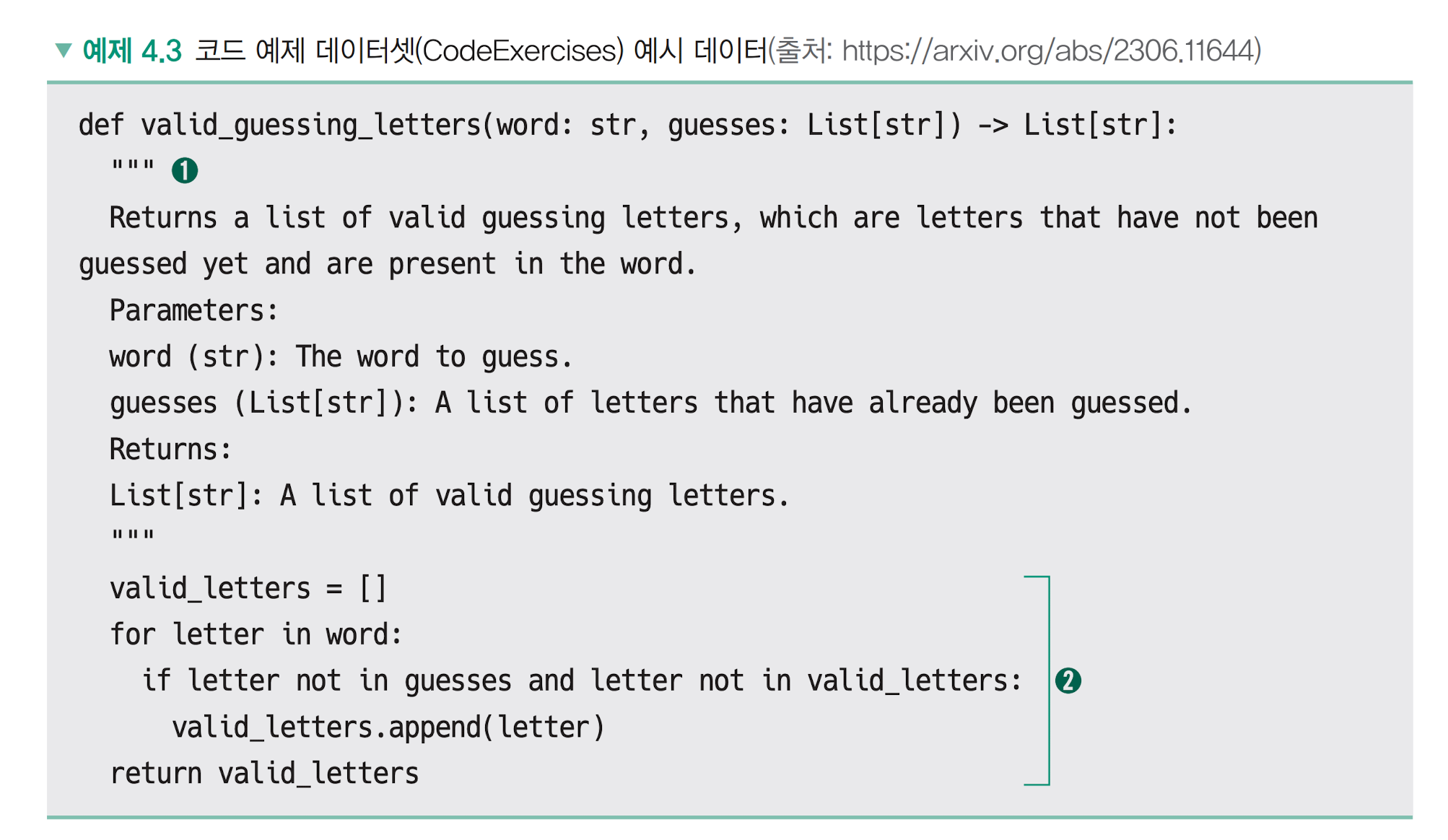
def valid_guessing_letters(word: str, guesses: List[str]) -> List[str]: """ Returns a list of valid guessing letters, which are letters that have not been guessed yet and are present in the word. Parameters: word (str): The word to guess. guesses (List[str]): A list of letters that have already been guessed. Returns: List[str]: A list of valid guessing letters. """ valid_letters = [] # 유효한 추측 문자를 저장할 빈 리스트 초기화 for letter in word: # 단어의 각 문자를 순회 if letter not in guesses and letter not in valid_letters: # 현재 문자가 아직 추측되지 않았고, 유효한 추측 문자 목록에도 없는 경우 valid_letters.append(letter) # 유효한 추측 문자 목록에 추가 return valid_letters # 유효한 추측 문자 목록 반환word(단어, str) : The word to guess ( 맞춰야 하는 단어)
guesses( List[str]): A list of letters that have already been guessed ( 이미 추측한 문자들의 리스트 )
Response : word 중 guessed 에 없는 letter
실행 예 apple, banana
word = "apple" guesses = ["a", "e"] result = valid_guessing_letters(word, guesses) print(result) # 출력: ['p', 'l'] word = "banana" guesses = ["b", "n"] result = valid_guessing_letters(word, guesses) print(result) # 출력: ['a']교육적 가치가 높은 데이터를 필터링하고, 코드 예제 데이터셋을 추가했을 때 모델 성능이 아래처럼 좋아짐

공개된 코드 데이터셋 : 스택+ 17
교육적 가치 높은 데이터 선별한 코드 텍스트북 : 29
GPT-3.5로 생성한 고품질의 예제 데이터셋으로 추가 학습 : 51
좋은 지시 데이터셋이 갖춰야 하는 조건
01. 지시 데이터셋을 작은 규모로 구축하더라도 모델이 지시사항의 형식을 인식하고, 답변하도록 만들 수 있다
02. 지시사항이 다향한 형태이고 답변의 품질이 높을수록 모델의 답변 품질도 높아진다.
03. 학습 데이터의 품질을 높이기 위해 모델의 목적에 맞춰 학습 데이터의 교육적 가치를 판단하고 교육적 가치가 낮은 데이터를 필터링하는 방법을 사용할 수 있다
04. 교재의 예제 데이터와 같은 고품질의 데이터를 학습 데이터에 추가하면 성능을 크게 높일 수 있다
책 출처 : https://ridibooks.com/books/3649000042
LLM을 활용한 실전 AI 애플리케이션 개발
LLM을 활용한 실전 AI 애플리케이션 개발 작품소개: 트랜스포머 아키텍처부터 RAG 개발, 모델 학습, 배포, 최적화, 운영까지 라마인덱스와 LLM을 활용한 AI 애플리케이션 개발의 모든 것이 책에서는
ridibooks.com
'LLM > LLM을 활용한 실전 AI 애플리케이션 개발' 카테고리의 다른 글
4.3 강화 학습이 꼭 필요할까? (0) 2025.01.27 4.2 채점 모델로 코드 가독성 높이기 (0) 2025.01.27 2장 토큰화와 Emdeding Python code 예 (0) 2025.01.18 1.4 LLM의 미래: 인식과 행동의 확장 (0) 2025.01.12 1.3 LLM 애플리케이션의 시대가 열리다 (0) 2025.01.12