-
4.3 강화 학습이 꼭 필요할까?LLM/LLM을 활용한 실전 AI 애플리케이션 개발 2025. 1. 27. 17:30
목차
4.3 강화 학습이 꼭 필요할까?
강화 학습 없이 LLM이 사람들이 더 선호하는 답변을 생성할 수 있도록 학습시키는 여러 방법을 살펴본다.
먼저, 여러 생설 결과 중 리워드 모델이 가장 높은 점수를 준 결과를 LLM의 지도 미세 조정에 사용하는 기각 샘플링(rejection sampling)방법을 알아본다.
다음으로 선호 데이터셋을 직접 LLM이 학습하는 방식으로 변경해 열풍을 일으킨 직접 선호 최적화(DPO, Direct Preference Optimization)에 대해 살펴본다
4.3.1 기각 샘플링: 단순히 가장 점수가 높은 데이터를 사용한다면?
기각 샘플링 : 제출된 코드 중 가장 가독성 점수가 높은 코드를 보고 참고해 학습 방향성을 잡는 방식
지도 미세 조정을 마친 LLM을 통해 여러 응답을 생성하고 그중에서 리워드 모델이 가장 높은 점수를 준 응답을 모아 다시 지도 미세 조정을 수행한다. 강화 학습을 사용하지 않기 때문에 학습이 비교적 안정적이고 간단하고 직관적인 방법임에도 효과가 좋아 많이 활용된다
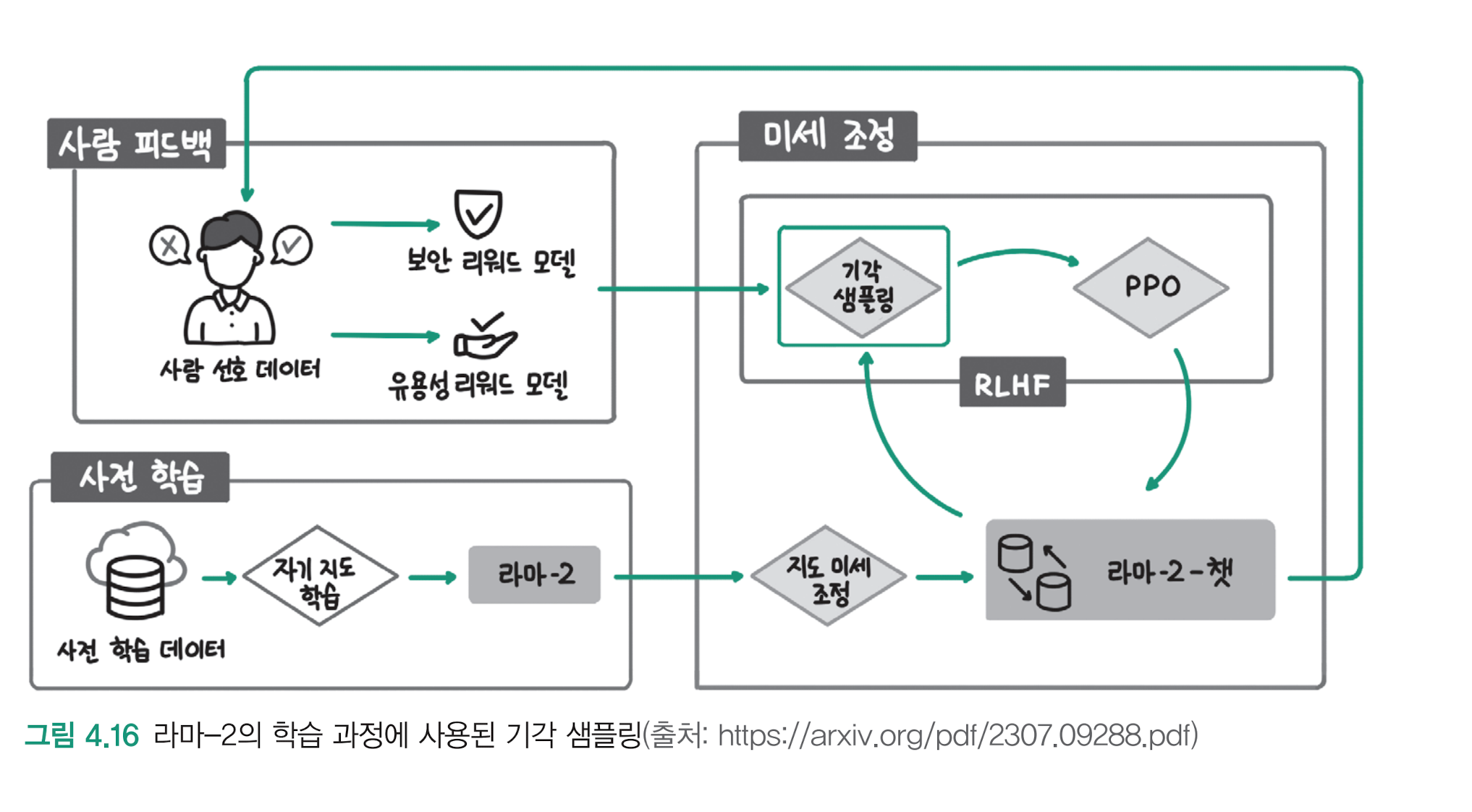
LLama2 도 학습 과정에서 기각 샘플링을 사용했다
01. 그림의 왼쪽 아래 부분처럼, 대용량의 사전 학습 데이터를 사용해 자기 지도 학습(Self-supervised learning)을 수행한다.
자기 지도 학습이란 데이터의 특성을 활용한 비지도 학습(unsupervised learning) 방식을 말하는데, 다음 단어를 예측하는 언어 모델링 방법을 사용했다고 이해하면 된다
02. 지도 미세 조정을 통해 라마-2-챗 모델을 만든다.
03. 그림 왼쪽 위에서 라마-2-챗 모델이 더 안전하고 사람들에게 도움이 될 수 있도록 사람의 피드백을 반영한 선호 데이터셋을 구축하고
04. RLHF를 통해 사람들이 선호하는 답변을 하도록 학습한다
RLHF 과정에 기각 샘플링이 추가된 것을 확인할 수 있다.
PPO를 통해 모델이 사람의 선호를 학습하도록 하지 않고, 먼저 기각 샘플링을 통해 언어 모델이 더 빠르고 안정적으로 사람의 선호를 학습한 후 PPO를 사용했다.
(cf 이전에는 PPO -> 기각 샘플링이였는데, 반대로 했다)
4.3.2 DPO: 선호 데이터셋을 직접 학습하기
채점 기능은 개발하는데 오랜 기간이 걸렸고, 새로운 유형의 코딩 테스트 문제를 추가하면 잘 작동하는지 매번 확인하는 데 많은 노력이 들었다. 그래서 채점 기능을 없애면서도, 사용자들에게 코드 가독성 훈련 기능을 제공할 방법을 고민하기 시작했다
LLM의 선호학습에 RLHF를 사용하게되면, 좋은 리워드 모델을 만들고 관리하는 것도 쉽지 않은 일이고, 리워드 모델을 만든다고 하더라도 리워드 모델에 강화 학습으로 사람의 선호를 반영한다는 것도 쉽지 않았다.
DPO(Direct Preference Optimization)
DPO 방법은 RLHF에 비해 훨씬 단순하면서 효과적이어서 많은 연구자와 개발자들이 환호했다.

RLHF는 선호 데이터셋으로 리워드 모델을 만들고 언어 모델의 출력을 평가하면서 강화 학습을 진행한다.
DPO에서는 선호 데이터셋을 직접 언어 모델에 학습시킨다
DPO 데이터셋 예
입력 프롬프트 : 최고의 프로그래밍 언어는?
선호 데이터 : 파이썬
비선호 데이터 : 자바
모델이 파이썬을 예측할 확률이 높아지도록, 자바는 확률이 낮아지도록 학습한다

참고 모델의
파이썬 30%
자바 15%
DPO 학습 후 모델
파이썬 33%
자바 13%
관련 논문 : 당신의 언어 모델은 리워드 모델이기도 하다
DPO 학습 전에 지도 미세 조정을 하지 않은 경우 성능이 증가하지 않았다
지도 미세 조정을 거치지 않은 언어 모델은 지시사항과 응답의 형식을 이해하기 어려워했기 때문이다.
논문 : Zephyr: Direct Distillation of LM Alignment
4.3.3 DPO를 사용해 학습한 모델들
DPO 를 사용하려면, 여전히 선호 데이터셋의 사전 구축이 필요하며, 많은 시간과 노력이 필요하다
더 효율적으로 선호 데이터셋을 구축하기 위한 방법과 더 큰 모델에서도 DPO가 잘 동작하는지 확인해 본다
제퍼-7b-베타(zephyr-7b-beta)AI 평가를 사용해 DPO학습 데이터를 구축했다.
제퍼는 4개의 LLM 이 생성한 결과를 AI(예:GPT-4)가 평가하고 가장 높은 점수를 받은 선호 데이터와 나머지 3개 중 랜덤으로 선택한 비선호 데이터 쌍을 구축해 dDPO를 수행했다.
dDPO 의 d 는 다른 LLM이 생성한 데이터를 활용했기 때문에 지식 증류(knowledge distillation)을 했다는 의미다.
제퍼는 발표 당시 최고 성능의 사전 학습 모델로 DPO가 성공적으로 동작하고 더 나아가 사람의 평가가 아닌 AI의 평가로도 잘 동작한다는 사실을 확인시켜 줬다.
인텔이 발표한 뉴럴-챗-7B(neural-chat-7b-v3-1)는 DPO학습을 수행한 모델로,
DPO 학습 데이터로 Intel/orca_dpo_pairs 를 사용했는데,
별도로 사람이나 AI가 선호를 판단하지 않고, GPT-3.5 또는 GPT-4가 생성한 답변을 선호 데이터로,
라마-2-13B 모델이 생성한 답변을 비선호 데이터로 사용했다.
사람이 직접 선호 데이터를 구축하거나 평가를 수행한 이전 연구와 달리, 더 성능이 뛰어난 모델의 생성 결과를 선호 데이터로 선택함으로써 학습 과정을 더 단순화 했다.
또한 앨런AI(Allen AI)의 튈루-2( TULU2) 모델은 파라미터가 700억 개인 모델에서도 DPO를 통해 사람의 선호를 학습시킬 수 있다는 점을 확인했다.
4.4 정리
언어 모델은
01. 먼저 대용량의 말뭉치(corpus)를 언어 모델링 방식으로 사전 학습하고,
02. 지시사항과 그에 대한 응답으로 구성된 지시 데이터셋으로 지도 미세 조정을 수행한다.
03. 더 나아가 사람들이 선호하는 방식으로 답변을 생성하고, 더 안전한 모델이 될 수 있도록 선호 데이터셋을 활용해 모델을 조정한다
선호 학습 방법은 2가지로
01. OpenAI가 챗GPT를 만들 때 리워드 모델과 강화 학습을 사용했다
- 하지만 강화 학습은 까다로워, 선호 학습 방법이 나왔다
02. 기각 샘플링은 강화 학습을 사용하지 않고, 리워드 모델로 부터 높은 점수를 받은 결과로 지도 미세 조정을 수행해, 선호 학습을 더 안정적으로 만들어 준다
03. DPO는 강화 학습은 물론 리워드 모델도 필요 없어 2024년 기준 가장 사랑받는 선호 학습 방법이 됐다.
* corpus [ˈkɔːrpəs] 명사 전문 용어 말뭉치, 코퍼스 (→habeas corpus)
distillation
바닷물을 끓여서, 소금을 거르고, 깨끗한 물만 증류(distill)
마찬가지로 다른 LLM 에서 필요한 데이터만 증류해서(distill,뽑아서) 사용했다라는 의미로 사용함
기각 샘플링의 기본 개념
- 샘플 생성: 모델이 데이터를 생성합니다. 예를 들어, LLM이 다음 단어를 확률적으로 선택합니다.
- 조건 검사: 생성된 샘플(예: 단어나 문장)이 특정 조건을 만족하는지 검사합니다.
- 기각 여부 결정:
- 조건을 만족하면 해당 샘플을 채택(accept)합니다.
- 조건을 만족하지 못하면 해당 샘플을 기각(reject)하고 새로운 샘플을 생성합니다.
- 반복: 조건을 만족하는 샘플이 생성될 때까지 과정을 반복합니다.
LLM(대형 언어 모델)에서 **기각 샘플링(reject sampling)**은 확률 분포에서 샘플을 생성하는 방법 중 하나로, 특히 목표로 하는 분포와 다른 분포를 사용하여 샘플을 생성한 후, 이를 조정하여 원하는 분포에 맞게 만드는 기법입니다. 이 방법은 Monte Carlo 방법의 일종으로, 복잡한 분포에서 샘플링할 때 유용합니다.
기각 샘플링의 기본 개념
- 목표 분포(Target Distribution): 우리가 샘플링하고자 하는 원래의 확률 분포 p(x). 이 분포는 직접 샘플링하기 어려울 수 있습니다.
- 제안 분포(Proposal Distribution): 샘플링이 쉬운 분포 q(x). 이 분포는 목표 분포와 유사하지만, 샘플링이 더 간단합니다.
- 기각 기준(Rejection Criterion): 제안 분포에서 생성된 샘플을 목표 분포에 맞게 조정하기 위한 조건입니다. 일반적으로 와 q(x)의 비율을 사용합니다.
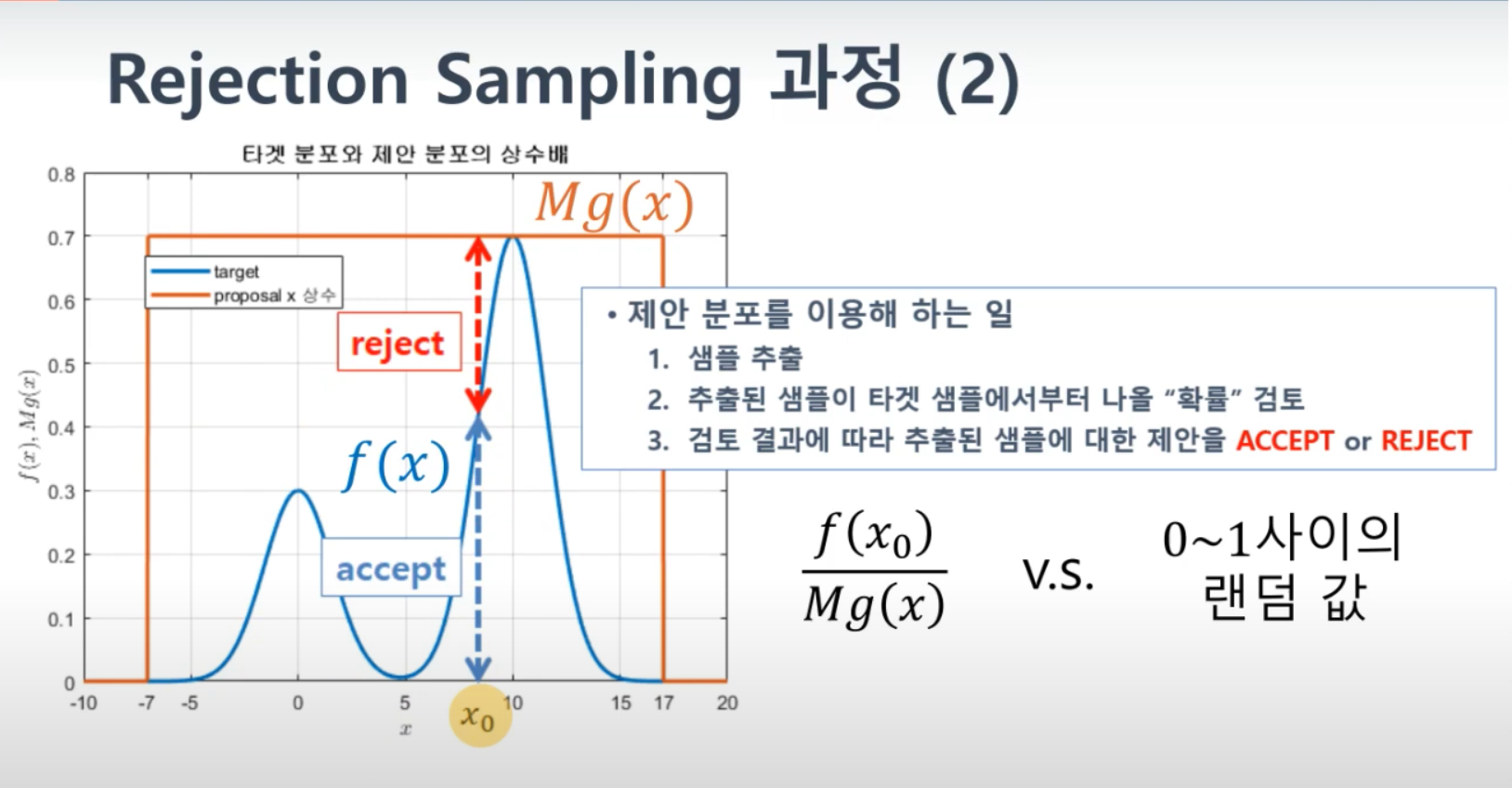
기각 샘플링의 과정
- 제안 분포에서 샘플링: 에서 샘플 를 생성합니다.
- 기각 기준 계산: 와 의 비율을 계산합니다. 이를 위해 M⋅q(x)≥p(x) 를 만족하는 상수 을 선택합니다.
- 기각 또는 수락: u를 [0, 1] 범위의 균일 분포에서 생성된 난수라고 할 때, 다음 조건을 확인합니다
u≤p(x)/M⋅q(x)- 조건이 참이면 를 샘플로 수락합니다.
- 조건이 거짓이면 x를 기각하고 다시 새로운 샘플을 생성합니다.
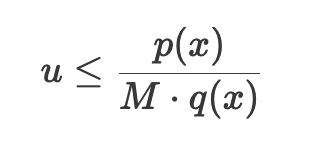
import random def generate_text(): # 임의의 문장 생성 samples = [ "AI is transforming industries.", "Nature is beautiful.", "Machine learning is fascinating.", "I love programming.", "AI is the future." ] return random.choice(samples) def reject_sampling(): while True: text = generate_text() # 조건: "AI"가 포함된 문장만 채택 if "AI" in text: return text result = reject_sampling() print("선택된 문장:", result) # result # 선택된 문장 : AI is the future.AI 가 포함된 문장만 선택하는 기각 샘플링 예
기각 샘플링 복잡한 예
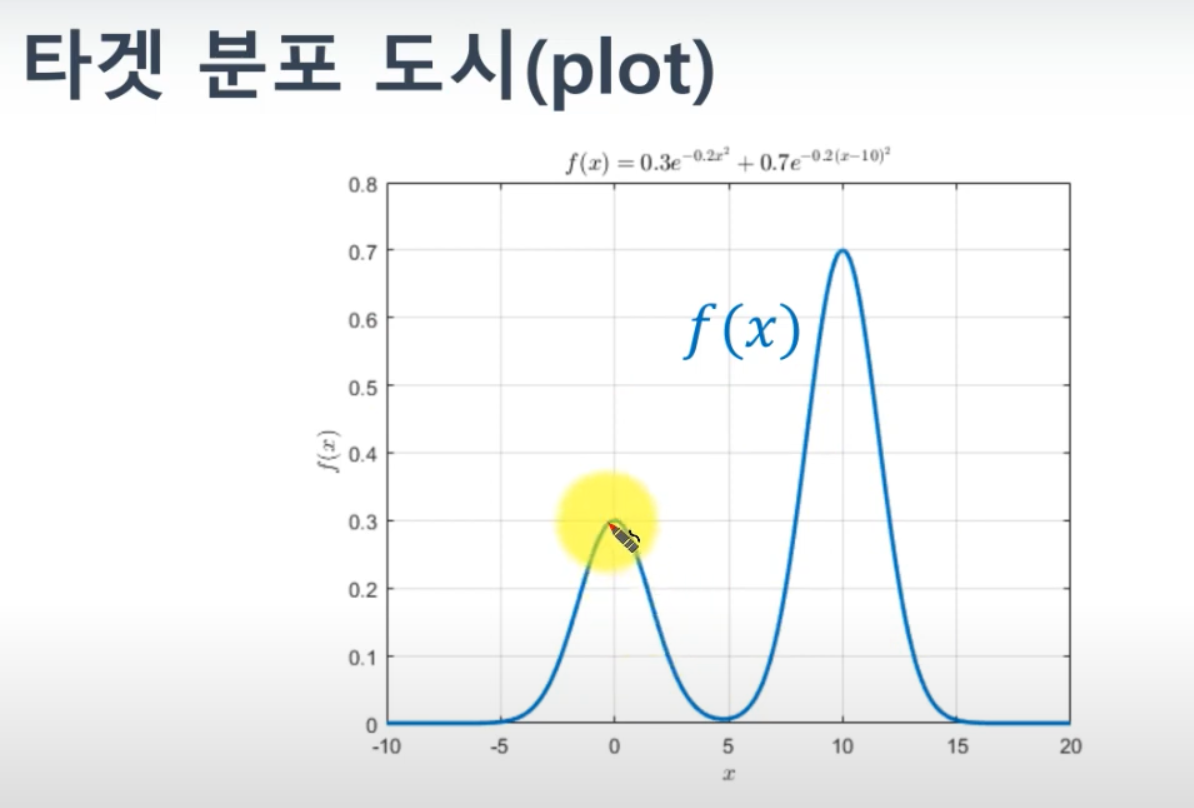

코드로
import numpy as np import random def target_distribution(x): """ 목표 분포 p(x) (임의의 함수) p(x) = 0.3 * exp(-0.2x^2) + 0.7 * exp(-0.2(x-10)^2) """ return 0.3 * np.exp(-0.2 * x**2) + 0.7 * np.exp(-0.2 * (x-10)**2) def proposal_distribution_max(): # 제안 분포 q(x)의 최대값 return 1.0 samples = [] num_samples = 1000 num_accepted = 0 for _ in range(num_samples): x = random.uniform(0, 1) # q(x)에서 x 샘플링 (0~1 사이의 균등 분포 가정) y = random.uniform(0, proposal_distribution_max()) # y 샘플링 if y <= target_distribution(x): samples.append(x) num_accepted += 1 print(f"총 {num_samples}개 샘플 중 {num_accepted}개 수락됨") # result # 1차 : 총 1000개 샘플 중 277개 수락됨 # 2차 : 총 1000개 샘플 중 282개 수락됨참고 : https://www.youtube.com/watch?v=7wtVFfwAps4
책 출처 : https://ridibooks.com/books/3649000042
LLM을 활용한 실전 AI 애플리케이션 개발
LLM을 활용한 실전 AI 애플리케이션 개발 작품소개: 트랜스포머 아키텍처부터 RAG 개발, 모델 학습, 배포, 최적화, 운영까지 라마인덱스와 LLM을 활용한 AI 애플리케이션 개발의 모든 것이 책에서는
ridibooks.com
'LLM > LLM을 활용한 실전 AI 애플리케이션 개발' 카테고리의 다른 글
4.2 채점 모델로 코드 가독성 높이기 (0) 2025.01.27 4장 말 잘 듣는 모델 만들기 4.1 코딩 테스트 통과하기 (1) 2025.01.26 2장 토큰화와 Emdeding Python code 예 (0) 2025.01.18 1.4 LLM의 미래: 인식과 행동의 확장 (0) 2025.01.12 1.3 LLM 애플리케이션의 시대가 열리다 (0) 2025.01.12