-
4.2 채점 모델로 코드 가독성 높이기LLM/LLM을 활용한 실전 AI 애플리케이션 개발 2025. 1. 27. 14:50
목차
가동성 좋은 코드 위해,
코드 가독성을 평가하는 딥러닝 모델을 코딩 테스트에 포함시켜 봅니다
4.2.1 선호 데이터셋을 사용한 채점 모델 만들기

그림 4.8 코드 가독성 채점 모델을 만들기 위한 학습 데이터 형태 선호 데이터 셋 preference dataset 학습방법 :
코드 A 와 코드 B 를 비교해 더 가독성이 높은 코드를 선택하도록 합니다.
선택한 코드를 선호 데이터 chosen data
선택하지 않은 코드를 비선호 데이터 rejected data
* 코드 A만 보고, 가독성 점수를 매기기는 쉽지 않으므로, 코드 A,B 또는 B,C 를 비교하는 방식을 사용합니다.
예제 4.4 코드 가독성이 낮은 예시와 높은 예시
# 짝수 만 더하는 함수 # -------------------------- # 1 코드 가독성이 낮은 예시 def sum_even(nums): even_sum = sum(n for n in nums if n % 2 == 0) return even_sum # 2 코드 가독성이 높은 예시 def sum_of_even_numbers(numbers_list): """ Calculate the sum of all even numbers in a given list. Parameters: numbers_list (list): A list of integers. Returns: int: The sum of all even numbers in the list. """ even_numbers = [number for number in numbers_list if number % 2 == 0] total_sum = sum(even_numbers) return total_sum # result numbers = [1, 2, 3, 4, 5, 6] result = sum_even(numbers) print(result) # 출력: 12 (2 + 4 + 6)2의 코드가 1에 비해 가독성이 높은데
01. 독스트링(""")을 통해 함수에 대한 설명이 나와 있으며,
02-1. 짝수를 찾는 과정 even_numbers = ~~
02-2. 합계를 구하는 과정 total_sum = ~ 으로 각 line 이 1개의 작업만 처리하여 가독성이 높다.
03. 또 변수명도 데이터의 의미를 잘 반영하고 있다.
이렇게 여러 코드를 바탕으로 어떤 코드가 더 가독성이 높은지를 선택해 선호 데이터셋을 구축하고 나면,
채점 모델이 선호 데이터에 높은 점수를 주도록 채점 모델을 학습 시킨다
이런 방식으로 코드 가독성을 평가하는 채점 모델을 만들 수 있다

그림 4.10 ChatGPT를 학습하는 과정에서의 선호 데이터셋 구축과 리워드 모델 학습 OpenAI 도 ChatGPT를 개발하는 과정에서 같은 학습 방식을 사용했다
지도 미세 조정을 마친 LLM 은 사용자 요청에 맞춰 응답하기 때문에 사용자에게 결과적으로 해가 될 수 있는 정보 (예: 약물 제조, 폭탄 제조 방법)도 제공하고 차별적인 답변도 생성하는 문제가 있었는데, 답변의 점수를 평가하는 리워드 모델( reward model ) 을 만들었다.
그림 4.10 처럼 labeler 가 A > C > B 로 점수를 평가하고 이를 모델이 다시 학습하도록 한다
4.2.2 강화 학습: 높은 코드 가독성 점수를 향해
작성한 코드가 가독성 평가에서 60점을 받았다면,
01. 반복된 부분을 함수로 묶거나
02. 변수명을 잘 짓는등
다양한 시도를 하면서, 가독성 높은 코드 작성하는 방법을 익혀나간다
RLHF ( Reinforcement Learning from Human Feedback )
사람의 피드백을 활용한 강화 학습

그림 4.11 과 같이 에이전트(Agent)가 환경(Environment)에서 행동(Action)을 한다.
행동에 따라 환경의 상태(state)가 바뀌고,(Rt+1, St+1) 행동에 대한 보상(Reward)이 생기는데,
에이전트는 이 변화된 상태를 인식하고 보상을 받는다.
에이전트는 가능하면 더 많은 보상을 받을 수 있도록 행동을 수정하면서 학습한다.
이때 에이전트가 연속적으로 수행하는 행동의 모음을 에피소드(episode)라고 한다
엔지니어스의 사용자는 채점 시스템의 점수를 받으며,
코드의 변수명을 바꾸거나, 공통 로직을 함수로 만들거나, 타입 힌트를 추가하는 등 여러 행동을 한다,.
이때 그림 4.11과 연결하면
사용자는 에이전트이고,
채점 시스템은 환경,
채점 시스템이 매긴 점수는 보상
행동을 통해 변화된 코드가 변화된 상태라고 할 수 있다.
사용자가 높은 점수를 받기 위해 한 여러 행동을 하나로 묶으면 에피소드가 된다.

RLHF를 통해 학습하는 과정
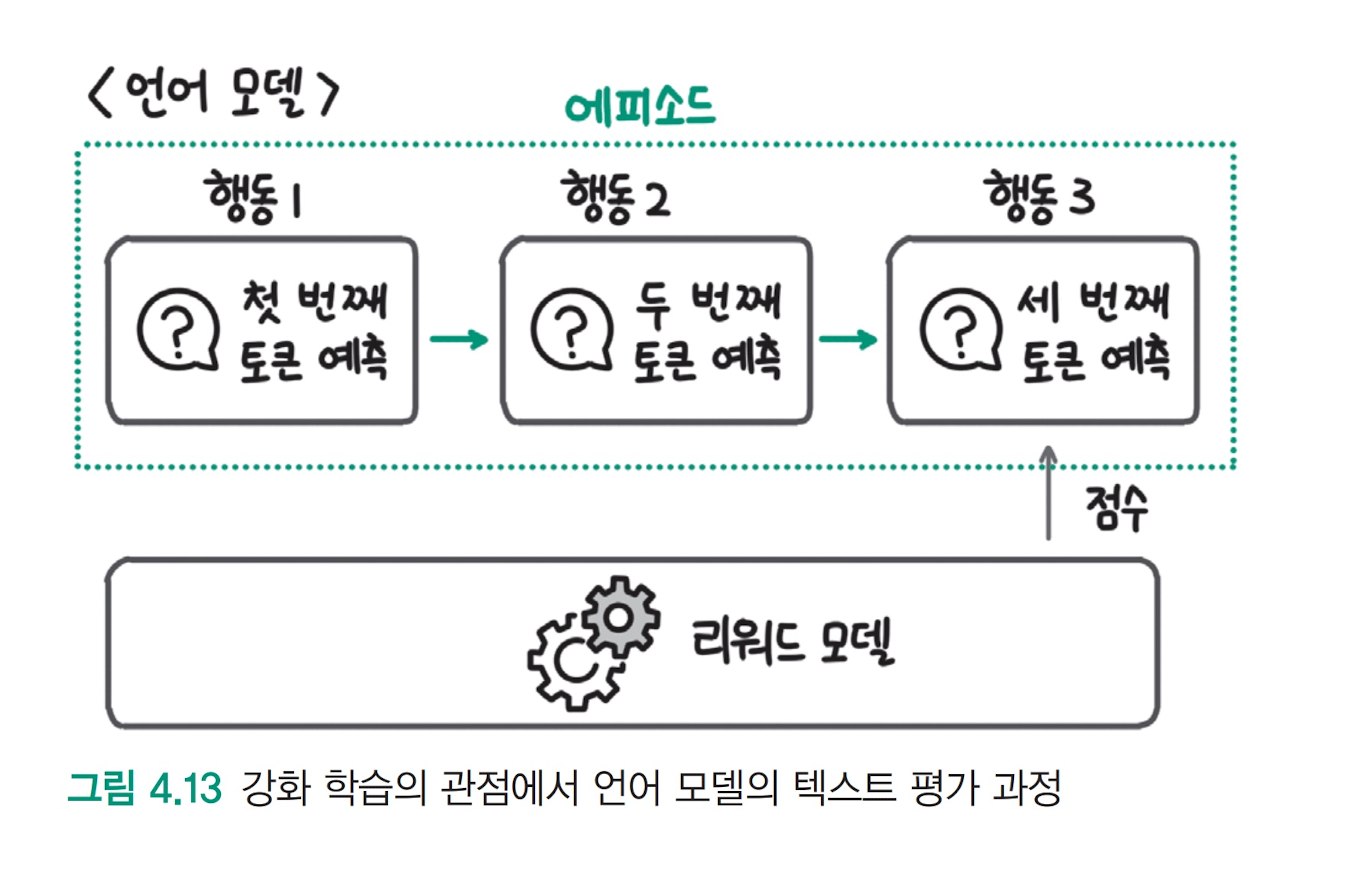
언어 모델은 다음 단어를 예측하는 방식으로 토큰을 하나씩 생성하는데,
강화 학습 관점에서는 토큰 생성을 하나의 행동으로 볼 수 있다.
언어 모델이 텍스트를 모두 생성하면,
리워드 모델이 생성한 텍스트를 평가하고 점수를 매긴다.
언어 모델은 생성한 문장의 점수가 높아지는 방향으로 학습한다.
이 때 보상을 높게 받는 데에만 집중하는 보상 해킹(reward hacking)이 발생할 수 있다
예로, 점수만을 위해 아예 쉬운 코드만 작성해서 print("hello world") 점수를 높게 받으려고 할 수 있다
OpenAI 는 보상 해킹을 피하기 위해 PPO 라는 강화 학습 방법을 사용했다
4.2.3 PPO: 보상 해킹 피하기

가독성 점수는 60 -> 90 으로 높아졌으나,
기능 구현 점수 80 -> 30 으로,
코드 효율성 점수는 70 -> 40 으로 떨어지는 보상 해킹 발생
평가 모델의 높은 점수를 받는 과정에서 다른 능력이 감소하거나,
평가 점수만 높게 받을 수 있는 우회로를 찾는 현상을 보상 해킹 이라고 한다
코드의 가독성을 높이기위해 한 번에 여러 부분을 수정하거나, 완전히 지우고 새로 작성하는 작업은 대단히 어렵다.
리워드 모델을 통해 LLM을 학습할 때도 비슷한 문제가 발생한다.
OpenAI는 이런 문제를 피하기 위해 강화 학습 방법 중 근접 정책 최적화(Proximal Preference Optimization)라는 학습 방법을 사용했다.
* proximal [|prɑːksɪməl] 형용사 해부 근위의, 몸 중심부 쪽의
즉, 모델이 너무 멀지 않게 가까운 범위에서 리워드 모델의 높은 점수를 찾도록 한다는 의미다.
이때, 지도 미세 조정 모델을 기준으로 거리를 측정하기 때문에 참고 모델(reference model)이라고 한다,.

너무 먼 90점인 A를 찾지 않고, 가까운 80점인 C를 찾는 학습방법
4.2.4 RLHF: 멋지지만 피할 수 있다면...
RLHF는 멋진 결과물만큼이나 사용하기 어렵기로 악명이 높다
리워드 모델의 성능이 좋지 않으면 LLM이 일관성 없는 점수를 통해 학습하게 되면서, 제대로 학습되지 않는다.
따라서 성능이 높고 일관성 있는(robust) 리워드 모델을 만들어야 한다.
또한 학습시킬 때 참고 모델, 학습 모델, 리워드 모델 총 3개의 모델이 필요하기 때문에, GPU와 같은 리소스가 더 많이 필요하다.
마지막으로 강화 학습 자체가 하이퍼파라미터에 민감하고 학습이 불안정하기 때문에, 많은 연구자와 개발자들이 RLHF를 활용해 LLM을 학습하는 데 어려움을 겪었다.
책 출처 : https://ridibooks.com/books/3649000042
LLM을 활용한 실전 AI 애플리케이션 개발
LLM을 활용한 실전 AI 애플리케이션 개발 작품소개: 트랜스포머 아키텍처부터 RAG 개발, 모델 학습, 배포, 최적화, 운영까지 라마인덱스와 LLM을 활용한 AI 애플리케이션 개발의 모든 것이 책에서는
ridibooks.com
'LLM > LLM을 활용한 실전 AI 애플리케이션 개발' 카테고리의 다른 글
4.3 강화 학습이 꼭 필요할까? (0) 2025.01.27 4장 말 잘 듣는 모델 만들기 4.1 코딩 테스트 통과하기 (1) 2025.01.26 2장 토큰화와 Emdeding Python code 예 (0) 2025.01.18 1.4 LLM의 미래: 인식과 행동의 확장 (0) 2025.01.12 1.3 LLM 애플리케이션의 시대가 열리다 (0) 2025.01.12