-
14장 Operator 7 - splitSpring/Webflux 2023. 7. 29. 17:26
github : https://github.com/bjpublic/Spring-Reactive/tree/main/part2/src/main/java/chapter14/operator_7_split
14.8 Flux Sequence 분할을 위한 Operator
1) windows
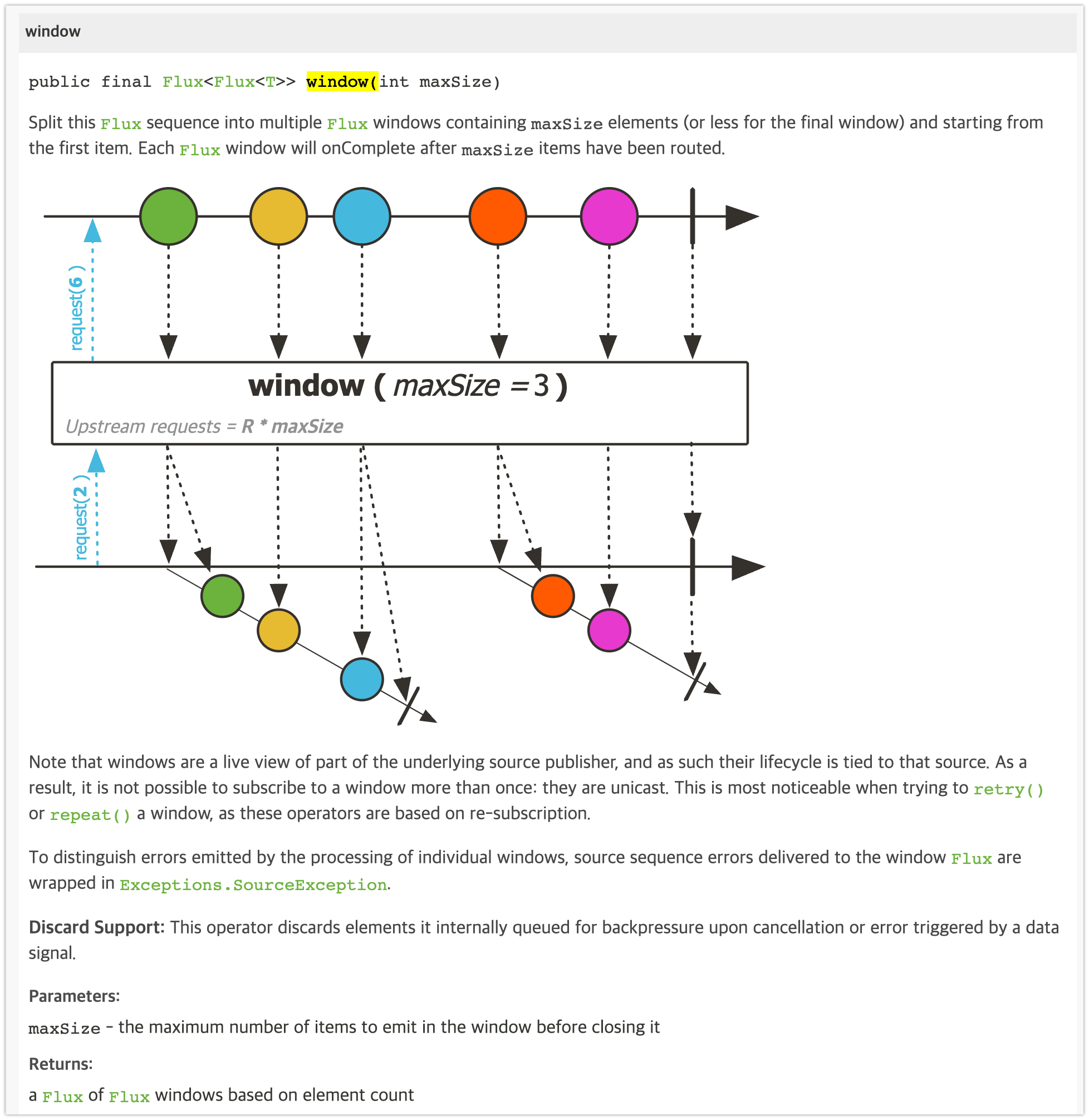
window(int maxSize) 는 Upstream 에서 emit 되는 첫 번째 데이터부터 maxSize 숫자만큼의 데이터를 포함하는 새로운 Flux 로 분할합니다. Reactor 에서는 이렇게 분할된 Flux 를 윈도우(window) 라고 부릅니다
코드 14-53 window 예제 1
public static void main(String[] args) { Flux.range(1, 11) .window(3) .flatMap(flux -> { log.info("======================"); return flux; }) .subscribe(new BaseSubscriber<>() { @Override protected void hookOnSubscribe(Subscription subscription) { subscription.request(2); } @Override protected void hookOnNext(Integer value) { log.info("# onNext: {}", value); request(2); } }); } // result > Task :Example14_53.main() 20:51:55.330 [main] reactor.util.Loggers DEBUG- Using Slf4j logging framework 20:51:55.356 [main] c.operator_7_split.Example14_53 INFO - ====================== 20:51:55.358 [main] c.operator_7_split.Example14_53 INFO - # onNext: 1 20:51:55.359 [main] c.operator_7_split.Example14_53 INFO - # onNext: 2 20:51:55.359 [main] c.operator_7_split.Example14_53 INFO - # onNext: 3 20:51:55.359 [main] c.operator_7_split.Example14_53 INFO - ====================== 20:51:55.359 [main] c.operator_7_split.Example14_53 INFO - # onNext: 4 20:51:55.360 [main] c.operator_7_split.Example14_53 INFO - # onNext: 5 20:51:55.360 [main] c.operator_7_split.Example14_53 INFO - # onNext: 6 20:51:55.360 [main] c.operator_7_split.Example14_53 INFO - ====================== 20:51:55.360 [main] c.operator_7_split.Example14_53 INFO - # onNext: 7 20:51:55.360 [main] c.operator_7_split.Example14_53 INFO - # onNext: 8 20:51:55.360 [main] c.operator_7_split.Example14_53 INFO - # onNext: 9 20:51:55.361 [main] c.operator_7_split.Example14_53 INFO - ====================== 20:51:55.361 [main] c.operator_7_split.Example14_53 INFO - # onNext: 10 20:51:55.361 [main] c.operator_7_split.Example14_53 INFO - # onNext: 11.window(3) 을 이용해 데이터를 3개씩 분할한 후,
flatMap 에서 구분선 "=============" 출력합니다
코드 14-54 window 예제 2
public static void main(String[] args) { Flux.fromIterable(SampleData.monthlyBookSales2021) .window(3) .flatMap(flux -> MathFlux.sumInt(flux)) .subscribe(new BaseSubscriber<>() { @Override protected void hookOnSubscribe(Subscription subscription) { subscription.request(2); } @Override protected void hookOnNext(Integer value) { log.info("# onNext: {}", value); request(2); } }); } public class SampleData { public static final List<Integer> monthlyBookSales2021 = Arrays.asList(2_500_000, 3_200_000, 2_300_000, 4_500_000, 6_500_000, 5_500_000, 3_100_000, 2_000_000, 2_800_000, 4_100_000, 6_200_000, 4_200_000); } // result > Task :Example14_54.main() 20:56:37.656 [main] reactor.util.Loggers DEBUG- Using Slf4j logging framework 20:56:37.799 [main] c.operator_7_split.Example14_54 INFO - # onNext: 8000000 20:56:37.807 [main] c.operator_7_split.Example14_54 INFO - # onNext: 16500000 20:56:37.807 [main] c.operator_7_split.Example14_54 INFO - # onNext: 7900000 20:56:37.807 [main] c.operator_7_split.Example14_54 INFO - # onNext: 145000002021년도 분기별 도서 매출액 구하는 예제 코드 입니다
.windows(3) 로 3개씩 분할한 후에 MathFlux.sumInt() 를 이용해 3개씩 분할된 합계를 구합니다
MathFlux
MathFlux 는 수학 계산을 위한 전용 Flux 로, MathFlux 를 사용하려면 reactor-extra 를 build.gradle 에 아래와 같이 의존 라이브러리로 추가해 주어야 합니다
implementation 'io.projectreactor.addons:reactor-extra:3.4.8'2) buffer
https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Flux.html#buffer-int-

buffer(int maxSize) 는 Upstream 에서 emit 되는 첫 번째 데이터부터 maxSize 숫자만큼의 데이터를 List 버퍼로 한 번에 emit 합니다
마지막 버퍼에 포함된 데이터의 개수는 maxSize보다 더 적거나 같습니다
코드 14-55 buffer 예제
public static void main(String[] args) { Flux.range(1, 95) .buffer(10) .subscribe(buffer -> log.info("# onNext: {}", buffer)); } // result > Task :Example14_55.main() 22:04:07.565 [main] reactor.util.Loggers DEBUG- Using Slf4j logging framework 22:04:07.573 [main] c.operator_7_split.Example14_55 INFO - # onNext: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 22:04:07.574 [main] c.operator_7_split.Example14_55 INFO - # onNext: [11, 12, 13, 14, 15, 16, 17, 18, 19, 20] 22:04:07.574 [main] c.operator_7_split.Example14_55 INFO - # onNext: [21, 22, 23, 24, 25, 26, 27, 28, 29, 30] 22:04:07.574 [main] c.operator_7_split.Example14_55 INFO - # onNext: [31, 32, 33, 34, 35, 36, 37, 38, 39, 40] 22:04:07.575 [main] c.operator_7_split.Example14_55 INFO - # onNext: [41, 42, 43, 44, 45, 46, 47, 48, 49, 50] 22:04:07.575 [main] c.operator_7_split.Example14_55 INFO - # onNext: [51, 52, 53, 54, 55, 56, 57, 58, 59, 60] 22:04:07.575 [main] c.operator_7_split.Example14_55 INFO - # onNext: [61, 62, 63, 64, 65, 66, 67, 68, 69, 70] 22:04:07.575 [main] c.operator_7_split.Example14_55 INFO - # onNext: [71, 72, 73, 74, 75, 76, 77, 78, 79, 80] 22:04:07.575 [main] c.operator_7_split.Example14_55 INFO - # onNext: [81, 82, 83, 84, 85, 86, 87, 88, 89, 90] 22:04:07.575 [main] c.operator_7_split.Example14_55 INFO - # onNext: [91, 92, 93, 94, 95]buffer(10) 으로 지정했기 때문에 Upstream 에서 emit 된 데이터가 최대 10개까지 버퍼에 담기면, List 버퍼 형태로 Downstream 에 emit 합니다
List 버퍼로 10개씩 한꺼번에 Subscriber 에 전달되어 출력됩니다
높은 처리량을 요구하는 애플리케이션이 있다면, 들어오는 데이터를 순차적으로 처리하기보다는 batch insert 같은 일괄 작업에 buffer() 를 이용해서 성능 향상을 기대할 수 있습니다.
3) bufferTimeout
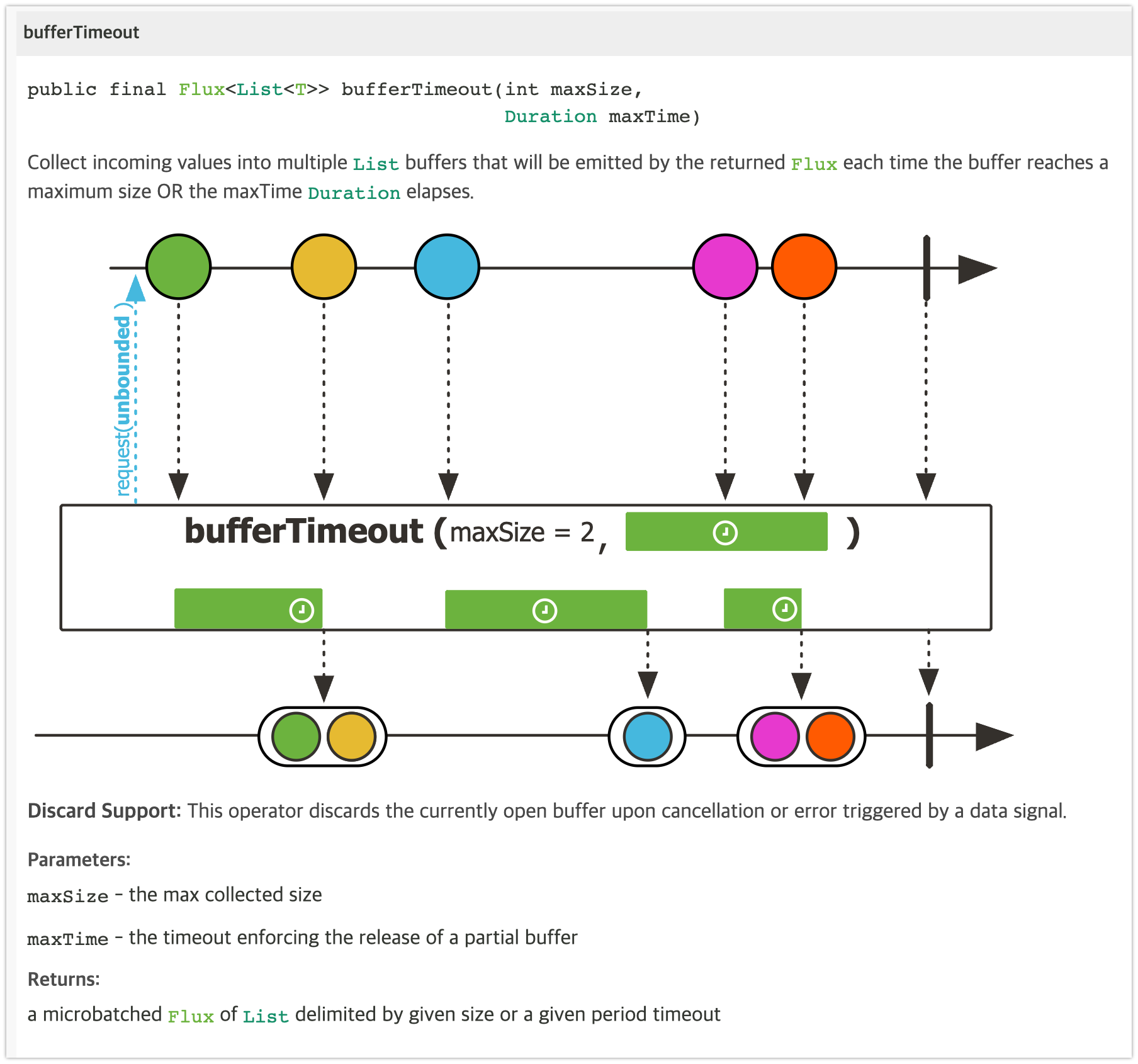
bufferTimeout(maxSize, maxTime) 은 Upstream 에서 emit 되는 첫 번째 데이터부터 maxSize 숫자만큼의 데이터 또는 maxTime 내에 emit 된 데이터를 List 버퍼로 한 번에 emit 합니다
bufferTimeout() 의 마블 다이어그램을 보면 파란색은 maxSize = 2 를 채우지 못했지만, timeout 조건에 부합되어 버퍼에 담겼습니다.
코드 14-56 bufferTimeout 예제
public static void main(String[] args) { Flux .range(1, 20) .map(num -> { try { if (num < 10) { Thread.sleep(100L); } else { Thread.sleep(300L); } } catch (InterruptedException e) { } return num; }) .bufferTimeout(3, Duration.ofMillis(400L)) .subscribe(buffer -> log.info("# onNext: {}", buffer)); } // result > Task :Example14_56.main() 22:10:31.802 [main] reactor.util.Loggers DEBUG- Using Slf4j logging framework 22:10:32.129 [main] c.operator_7_split.Example14_56 INFO - # onNext: [1, 2, 3] 22:10:32.438 [main] c.operator_7_split.Example14_56 INFO - # onNext: [4, 5, 6] 22:10:32.750 [main] c.operator_7_split.Example14_56 INFO - # onNext: [7, 8, 9] 22:10:33.455 [parallel-1] c.operator_7_split.Example14_56 INFO - # onNext: [10, 11] 22:10:34.066 [parallel-1] c.operator_7_split.Example14_56 INFO - # onNext: [12, 13] 22:10:34.670 [parallel-1] c.operator_7_split.Example14_56 INFO - # onNext: [14, 15] 22:10:35.272 [parallel-1] c.operator_7_split.Example14_56 INFO - # onNext: [16, 17] 22:10:35.880 [parallel-1] c.operator_7_split.Example14_56 INFO - # onNext: [18, 19] 22:10:36.078 [main] c.operator_7_split.Example14_56 INFO - # onNext: [20]num < 10 이면 0.1초를 sleep 하고
num >= 이면 0.3초를 sleep 합니다
bufferTimeout(3, 0.4초) 조건으로 데이터를 전달합니다.
10 미만에서는 3개씩 List 버퍼로 데이터가 전달되면,
10 이상에서는 2개씩 List 버퍼로 데이터가 전달됩니다
buffer(maxSize) Operator 의 경우, 입력으로 들어오는 데이터가 maxSize 가 되기 전에 어떤 오류로 인해 들어오지 못하는 상황이 발생할 경우, 애플리케이션은 maxSize 가 될때까지 무한정 기다리게 될 것입니다
따라서 bufferTimeout(maxSize, maxTime) Operator 를 사용함으로써, maxSize 만큼 데이터가 입력으로 들어오지 않더라도 maxTime 에 도달했을 때 버퍼를 비우게 해서 애플리케이션이 무한정 기다려야 되는 상황을 방지 할 수 있습니다.4) groupBy
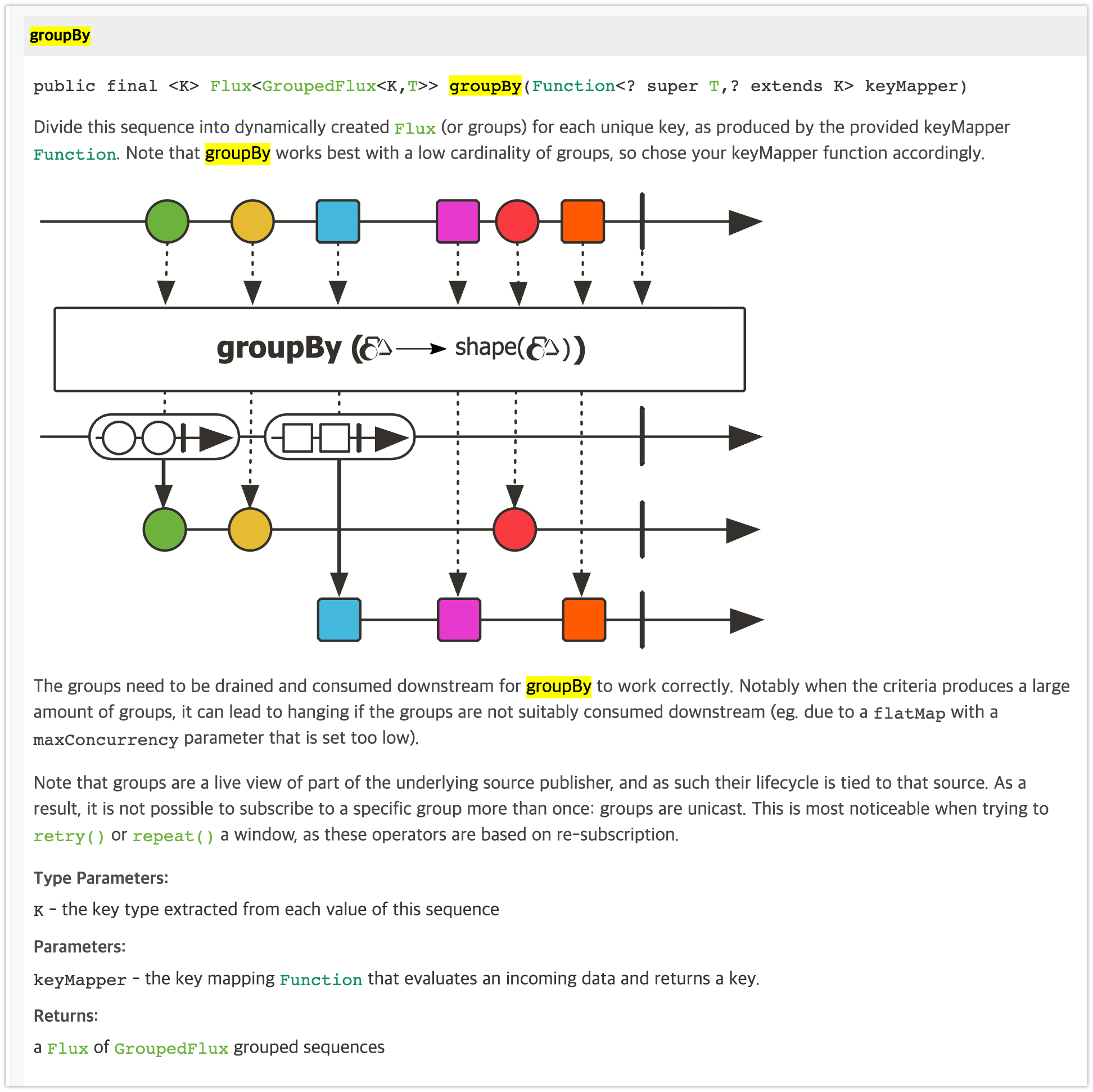
groupBy(keyMapper) 는 emit 되는 데이터를 keyMapper 로 생성한 key 를 기준으로 그룹화한 GroupedFlux 를 리턴하며,
이 GroupedFlux 를 통해서 그룹별로 작업을 수행할 수 있습니다.
코드 14-57 groupBy 예제 1
public static void main(String[] args) { Flux.fromIterable(SampleData.books) .groupBy(book -> book.getAuthorName()) .flatMap(groupedFlux -> groupedFlux .map(book -> book.getBookName() + "(" + book.getAuthorName() + ")") .collectList() ) .subscribe(bookByAuthor -> log.info("# book by author: {}", bookByAuthor)); } public class SampleData { public static final List<Book> books = Arrays.asList( new Book("Advance Java", "Tom", "Tom-boy", 25000, 100), new Book("Advance Python", "Grace", "Grace-girl", 22000, 150), new Book("Advance Reactor", "Smith", "David-boy", 35000, 200), new Book("Getting started Java", "Tom", "Tom-boy", 32000, 230), new Book("Advance Kotlin", "Kevin", "Kevin-boy", 32000, 250), new Book("Advance Javascript", "Mike", "Tom-boy", 32000, 320), new Book("Getting started Kotlin", "Kevin", "Kevin-boy", 32000, 150), new Book("Getting started Python", "Grace", "Grace-girl", 32000, 200), new Book("Getting started Reactor", "Smith", null, 32000, 250), new Book("Getting started Javascript", "Mike", "David-boy", 32000, 330) ); } // result > Task :Example14_57.main() 22:18:17.186 [main] reactor.util.Loggers DEBUG- Using Slf4j logging framework 22:18:17.279 [main] c.operator_7_split.Example14_57 INFO - # book by author: [Advance Kotlin(Kevin), Getting started Kotlin(Kevin)] 22:18:17.280 [main] c.operator_7_split.Example14_57 INFO - # book by author: [Advance Javascript(Mike), Getting started Javascript(Mike)] 22:18:17.280 [main] c.operator_7_split.Example14_57 INFO - # book by author: [Advance Java(Tom), Getting started Java(Tom)] 22:18:17.280 [main] c.operator_7_split.Example14_57 INFO - # book by author: [Advance Python(Grace), Getting started Python(Grace)] 22:18:17.281 [main] c.operator_7_split.Example14_57 INFO - # book by author: [Advance Reactor(Smith), Getting started Reactor(Smith)]author 로 groupBy 한 후 List 로 변환하여 subscriber 에 전달하는 예제 입니다
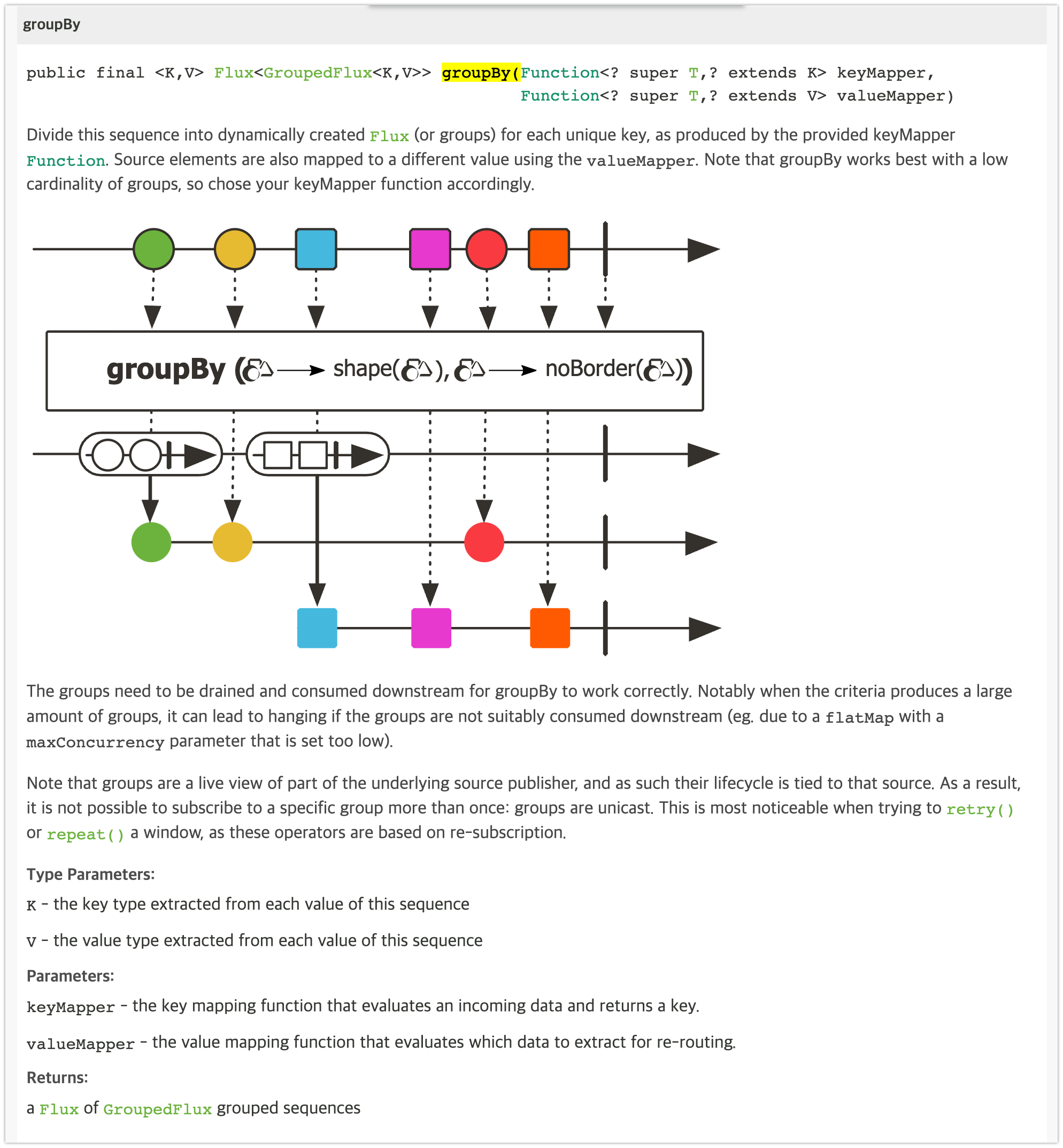
groupby(keyMapper, valueMapper) 의 마블다이어 그램입니다
groupBy 는 keyMapper 를 통해 생성되는 key 를 기준으로 emit 되는 데이터를 그룹화하지만,
groupby(keyMapper, valueMapper) 는 그룹화하면서 valueMapper를 통해 그룹화되는 데이터를 다른 형태로 가공 처리할 수 있습니다.
마블 다이어그램에서는 그룹화되는 도형들의 선이 제거된 후(valueMapper : noBorder) emit 되는 것을 볼 수 있습니다.
코드 14-58 groupBy 예제 2 ( keyMapper, valueMapper )
public static void main(String[] args) { Flux.fromIterable(SampleData.books) .groupBy(book -> book.getAuthorName(), book -> book.getBookName() + "(" + book.getAuthorName() + ")") .flatMap(groupedFlux -> groupedFlux.collectList()) .subscribe(bookByAuthor -> log.info("# book by author: {}", bookByAuthor)); } // result > Task :Example14_58.main() 22:28:47.763 [main] reactor.util.Loggers DEBUG- Using Slf4j logging framework 22:28:47.877 [main] c.operator_7_split.Example14_58 INFO - # book by author: [Advance Kotlin(Kevin), Getting started Kotlin(Kevin)] 22:28:47.879 [main] c.operator_7_split.Example14_58 INFO - # book by author: [Advance Javascript(Mike), Getting started Javascript(Mike)] 22:28:47.879 [main] c.operator_7_split.Example14_58 INFO - # book by author: [Advance Java(Tom), Getting started Java(Tom)] 22:28:47.879 [main] c.operator_7_split.Example14_58 INFO - # book by author: [Advance Python(Grace), Getting started Python(Grace)] 22:28:47.879 [main] c.operator_7_split.Example14_58 INFO - # book by author: [Advance Reactor(Smith), Getting started Reactor(Smith)]코드 14-57 에서는 2 줄에 나눠서 groupBy, flatMap 으로 각각 처리했으나,
.groupBy(book -> book.getAuthorName())
.flatMap(groupedFlux ->groupedFlux.map(book -> book.getBookName() +"(" + book.getAuthorName() + ")").collectList())코드 14-58 에서는 groupBy 와 mapping 을 한 번에 처리했습니다.
.groupBy(book ->book.getAuthorName(),book -> book.getBookName() + "(" + book.getAuthorName() + ")")
.flatMap(groupedFlux -> groupedFlux.collectList())코드 14-59 groupBy 예제 3
Flux.fromIterable(SampleData.books) .groupBy(book -> book.getAuthorName()) .flatMap(groupedFlux -> Mono .just(groupedFlux.key()) .zipWith( groupedFlux .map(book -> (int) (book.getPrice() * book.getStockQuantity() * 0.1)) .reduce((y1, y2) -> y1 + y2), (authorName, sumRoyalty) -> authorName + "'s royalty: " + sumRoyalty) ) .subscribe(log::info); } // result > Task :Example14_59.main() 22:34:49.786 [main] reactor.util.Loggers DEBUG- Using Slf4j logging framework 22:34:49.894 [main] c.operator_7_split.Example14_59 INFO - Kevin's royalty: 1280000 22:34:49.894 [main] c.operator_7_split.Example14_59 INFO - Mike's royalty: 2080000 22:34:49.895 [main] c.operator_7_split.Example14_59 INFO - Tom's royalty: 986000 22:34:49.895 [main] c.operator_7_split.Example14_59 INFO - Grace's royalty: 970000 22:34:49.895 [main] c.operator_7_split.Example14_59 INFO - Smith's royalty: 1500000groupBy(keyMapper) 를 이용해 저자별로 도서를 그룹화한 후에 그룹화한 도서가 수량만큼 모두 판매되었을 때 저자가 얻을 수 있는 수익을 계산하는 예제 입니다
.groupBy(book -> book.getAuthorName())
1) 저자명을 기준으로 도서를 그룹화 합니다
.flatMap(groupedFlux ->
Mono
.just(groupedFlux.key())2) 계산을 위해 flatMap 으로 평탄화 작업을 합니다
.zipWith(
groupedFlux
.map(book -> (int) (book.getPrice() * book.getStockQuantity() * 0.1))
.reduce((y1, y2) -> y1 + y2), (authorName, sumRoyalty) -> authorName + "'s royalty: " + sumRoyalty)4) '저자명: 총 인세 수익' 형태로 Subscriber 에게 전달하기 위해 zipwith(저자명, 총 인세 수익) 를 사용합니다
.reduce((y1, y2) -> y1 + y2), (authorName, sumRoyalty) -> authorName + "'s royalty: " + sumRoyalty)
6) reduce() 를 이용해 그룹화된 도서의 총 인세합을 계산하고,
autherName 과 sumRoyalty 하나의 string 으로 합쳐 줍니다
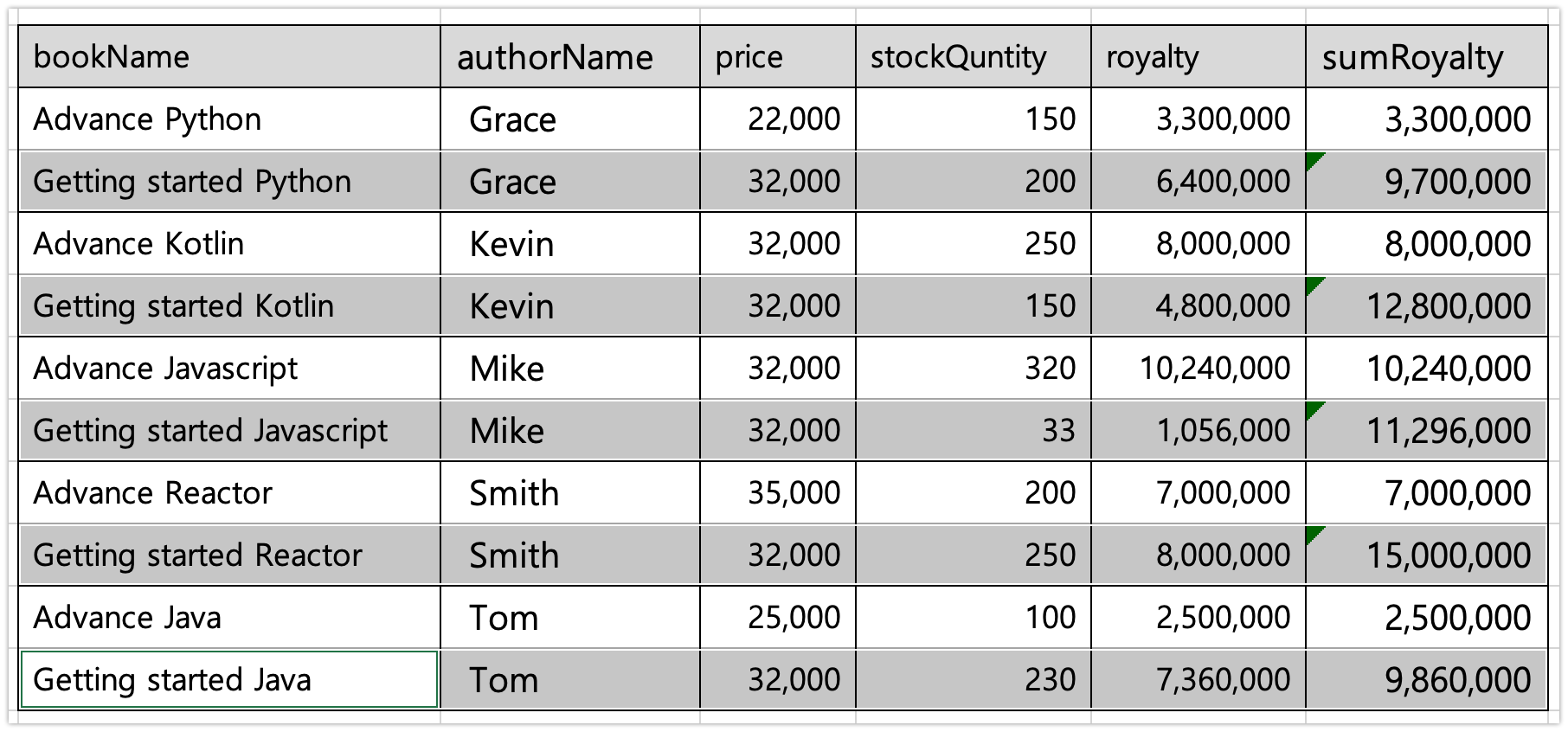
7) 계산된 총 인세 금액을 Subscriber 에게 전달합니다.
'Spring > Webflux' 카테고리의 다른 글
14장 Operator 8 - multicast (0) 2023.07.30 14장 Operator 6 - time (0) 2023.07.26 14장 Operator 5 - Error (0) 2023.07.22 14장 Operator 4 - peek (0) 2023.07.22 14장 Operator 3 - transformation (0) 2023.07.16