-
11장 ContextSpring/Webflux 2023. 5. 12. 20:59
1 Context란?
* context [ˈkɑːˌtɛkst] 2. the situation in which something happens, the group of conditions that exist where and when something happens 2. 어떤 일이 발생하는 상황, 어떤 일이 발생하는 장소와 시간에 존재하는 조건의 집합
1. the words that are used with a certain word or phrase and that help to explain its meaning
1. 특정 단어 또는 구와 함께 사용되며 그 의미를 설명하는 데 도움이 되는 단어예 : 아파서 병원 방문 시 의사에게 소개하는 전후 사정과 증상이 Context 에 해당합니다.
→ 어떠한 상황에서 그 상황을 처리하기 위해 필요한 정보
프로그래밍 세계에서의 몇 가지 예
- ServletContext 는 Servlet 이 Servlet Container 와 통신하기 위해서 필요한 정보를 제공하는 인터페이스
- Spring Framework 에서 ApplicationContext 는 애플리케이션의 정보를 제공하는 인터페이스 ApplicationContext 가 제공하는 대표적인 정보가 Spring Bean 객체
- Spring Security 에서 SecurityContextHolder 는 SecurityContext 를 관리하는 주체인데, 여기서의 Security Context 는 애플리케이션 사용자의 인증 정보를 제공하는 인터페이스입니다.
Reactor API 의 Context
A key/value store that is propagated between components such as operators via the context protocol.
즉, Reactor의 Context는 Operator 같은 Reactor 구성요소 간에 전파되는 key/value 형태의 저장소라고 정의한다.
ThreadLocal 과 유사하지만, 실행 스레드와 매핑되지 않고, Subscriber 와 매핑됩니다. 그래서 구독이 발생할 때마다 해당 구독과 연결된 하나의 Context 가 생깁니다.
public static void main(String[] args) throws InterruptedException { Mono .deferContextual(ctx -> Mono .just("Hello" + " " + ctx.get("firstName")) .doOnNext(data -> log.info("just doOnNext1 data:{}, firstName:{}", data, ctx.get("firstName"))) ) .subscribeOn(Schedulers.boundedElastic()) .publishOn(Schedulers.parallel()) .transformDeferredContextual( (mono, ctx) -> mono.map(data -> data + " " + ctx.get("lastName")) .doOnNext(data -> log.info("#map doOnNext2 data:{}, lastName:{}", data,ctx.get("lastName"))) ) .contextWrite(context -> context.put("lastName", "Jobs")) .contextWrite(context -> context.put("firstName", "Steve")) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(100L); } //result > Task :Example11_1.main() 21:32:09.775 [main] DEBUG- Using Slf4j logging framework 21:32:09.806 [boundedElastic-1] INFO - just doOnNext1 data:Hello Steve, firstName:Steve 21:32:09.816 [parallel-1] INFO - #map doOnNext2 data:Hello Steve Jobs, lastName:Jobs 21:32:09.816 [parallel-1] INFO - # onNext: Hello Steve Jobs주의깊게 볼 포인트
01. 원본 데이터 소스레벨에서 Context 데이터를 읽기 위해 deferContextual() 사용
02. Operator 체인의 중간에서 Context 데이터를 읽기 위해 transformDeferredContextual() 사용
03. emit 는 [boundedElastic-1] 스레드, 체인 중간 map 은 [parallel-1] 로 스레드가 다르지만, 구독별 context 를 공유하여, 읽을 수 있다.defer Operator
14번째 줄에서 컨텍스트에 쓰는데 .contextWrite(context -> context.put("lastName", "Jobs"))
3번째 줄과 10번째 줄에서 컨텍스트 내용을 읽기 위해 defer 연산자를 사용하였습니다.
: defer Operator 는 구독자의 인스턴스가 생성 될 때까지 defer 내부 코드 실행(emit) 을 지연시킵니다.실행결과
01. deferContext 에 의해 emit 이 지연되는 동안, contextWrite 됩니다.
.contextWrite(context -> context.put("lastName", "Jobs"))
.contextWrite(context -> context.put("firstName", "Steve"))02. deferContext 에 지연되었다가 구독시점에 emit 된 data 와 ctx.get("firstName") 출력합니다., [boundedElastic-1] 스레드
21:32:09.806 [boundedElastic-1] INFO - just doOnNext1 data:Hello Steve, firstName:Steve
03. map 된 data 와 ctx.get("lastName") 를 출력, [parallel-1] 스레드,
[boundedElastic-1] 와 [parallel-1] 로 스레드가 다르지만, 구독별 context 를 공유하여 firstName, lastName 둘다 가져옵니다.
21:32:09.816 [parallel-1] INFO - #map doOnNext2 data:Hello Steve Jobs, lastName:Jobs
04. 구독 onNext 에 최종 데이터 출력,
21:32:09.816 [parallel-1] INFO - # onNext: Hello Steve Jobs
Tips 람다 파라미터(ctx) 는 Context 타입의 객체가 아니라 ContextView 타입 객체입니다
데이터를 쓸 때는 Context 사용
데이터를 읽을 때는 ContextView 를 사용합니다.
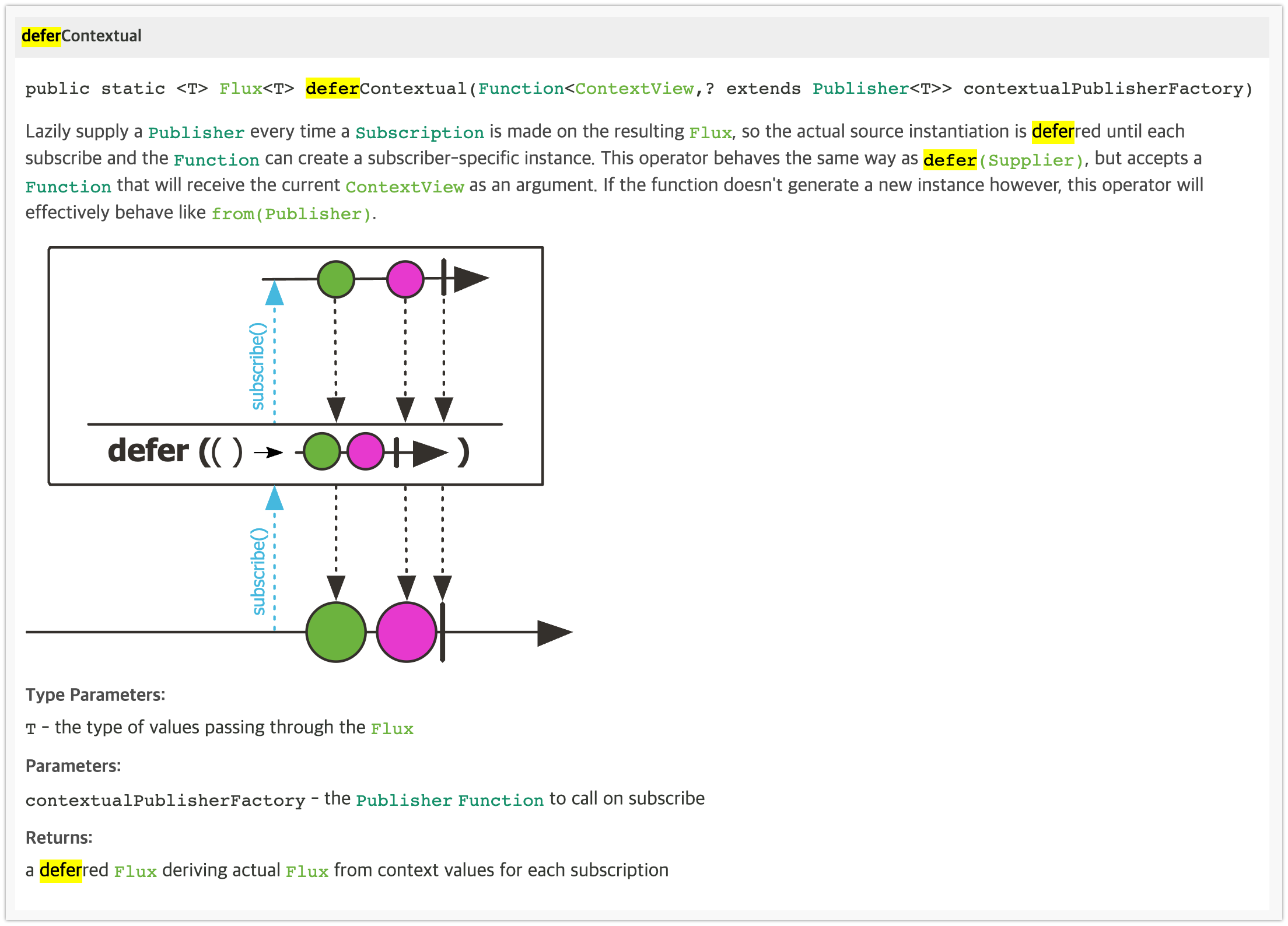
deferContextual()
은 defer() Operator 와 같은 원리로 동작하는데, Context 에 저장된 데이터와 원본 데이터 소스의 처리를 지연시키는 역할을 합니다. subscriber-specific instance 구독자의 특정 인스턴스 생성 시점까지 지연시킵니다.
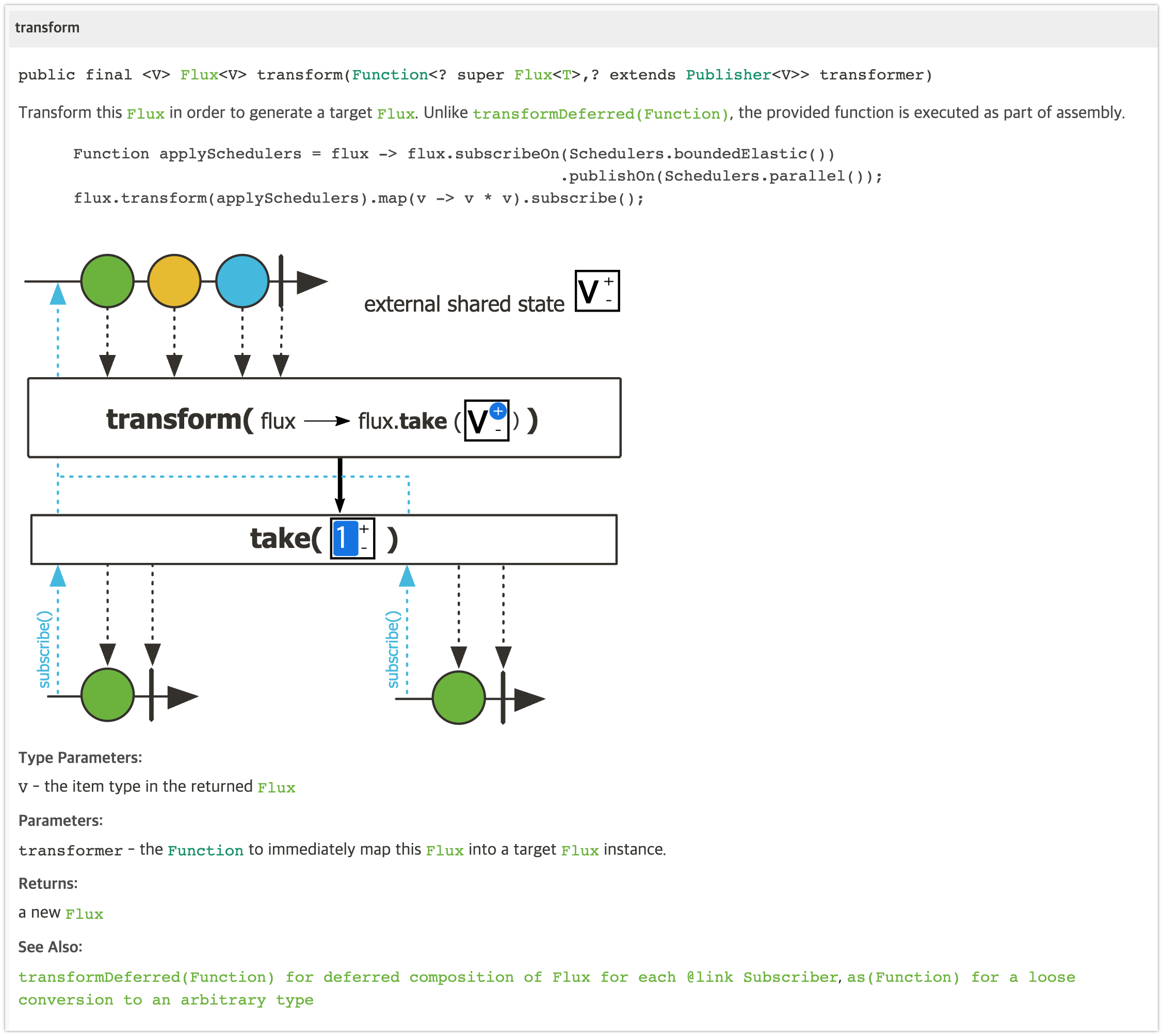
transform()
영어 : https://projectreactor.io/docs/core/release/reference/#_using_the_transform_operator
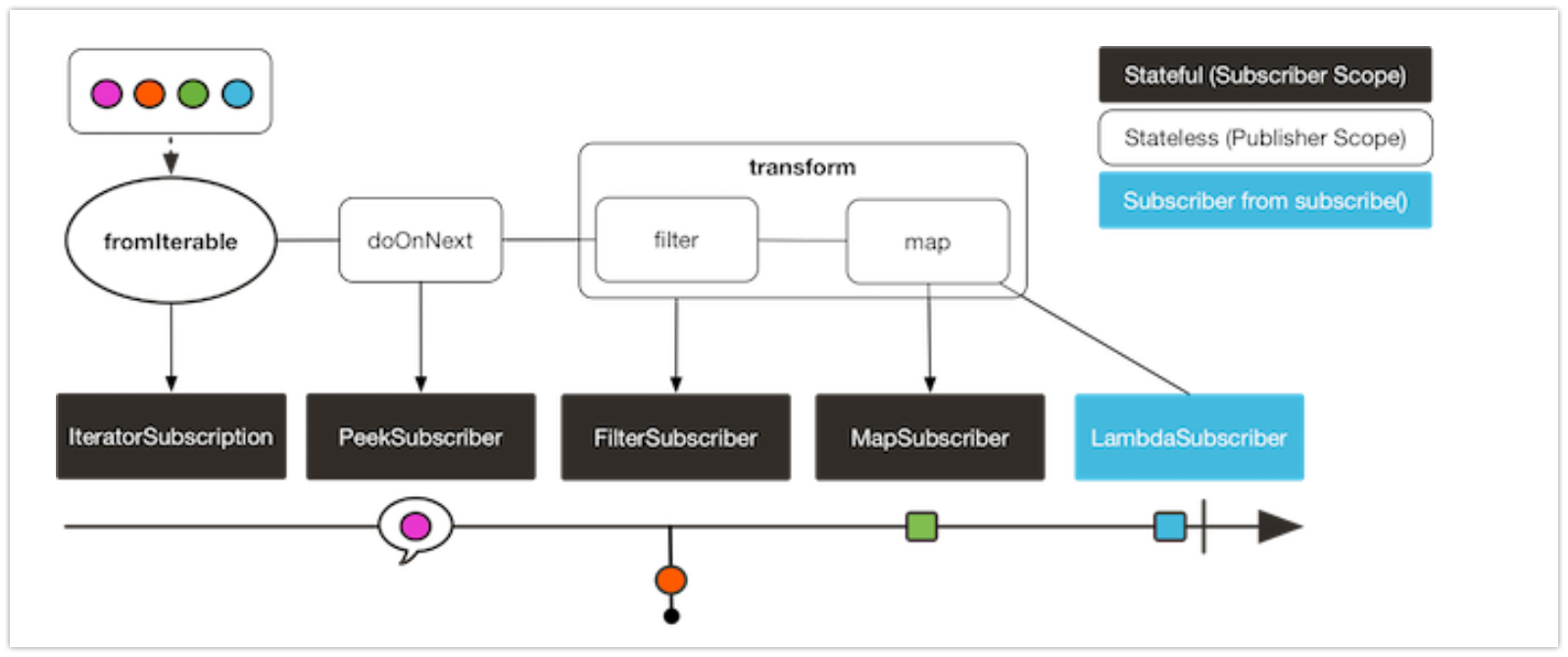
transform 연산자는 연산자 체인 일부를 하나의 함수로 캡슐화해 준다. 이 함수는 기존에 연결된 연산자 체인에 캡슐화한 연산자를 붙여준다. 이렇게 하면 시퀀스의 모든 구독자에 동일한 연산자를 적용하는데, 이는 기본적으로 직접 연산자를 체인에 추가하는 것과 동일하다. 예제는 아래 코드에 있다:
Function<Flux<String>, Flux<String>> filterAndMap = f -> f.filter(color -> !color.equals("orange")) .map(String::toUpperCase); Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple")) .doOnNext(System.out::println) .transform(filterAndMap) .subscribe(d -> System.out.println("Subscriber to Transformed MapAndFilter: "+d)); // result blue // .doOnNext(System.out::println) Subscriber to Transformed MapAndFilter: BLUE green Subscriber to Transformed MapAndFilter: GREEN orange purple Subscriber to Transformed MapAndFilter: PURPLEfilterAndMap 캡슐화한다. this Flux(filterAndMap) 를 대상 flux 로 캡슐화하여 generate 한다
transformDeffered()
영어 : https://projectreactor.io/docs/core/release/reference/#_using_the_transformdeferred_operator
transformDeffered 연산자도 transform과 유사하게 연산자를 함수 하나로 캡슐화한다.
가장 큰 차이점은 구독자마다 따로 적용한다는 것이다.
이 말은, 실제로는 구독자마다 다른 연산자 체인을 만든다는 뜻이다 (어떤 상태를 유지함으로써). 예제는 아래 코드에 있다:AtomicInteger ai = new AtomicInteger(); Function<Flux<String>, Flux<String>> filterAndMap = f -> { if (ai.incrementAndGet() == 1) { return f.filter(color -> !color.equals("orange")) .map(String::toUpperCase); } return f.filter(color -> !color.equals("purple")) .map(String::toUpperCase); }; Flux<String> composedFlux = Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple")) .doOnNext(System.out::println) .transformDeferred(filterAndMap); composedFlux.subscribe(d -> System.out.println("Subscriber 1 to Composed MapAndFilter :"+d)); composedFlux.subscribe(d -> System.out.println("Subscriber 2 to Composed MapAndFilter: "+d)); //result blue Subscriber 1 to Composed MapAndFilter :BLUE green Subscriber 1 to Composed MapAndFilter :GREEN orange purple Subscriber 1 to Composed MapAndFilter :PURPLE blue Subscriber 2 to Composed MapAndFilter: BLUE green Subscriber 2 to Composed MapAndFilter: GREEN orange Subscriber 2 to Composed MapAndFilter: ORANGE purplefilterAndMap
1 일때(첫번째 구독)은 orange 를 제외하고 대문자로 바꾸어 리턴 ( BLUE, GREEN, orange, PURPLE )
!1 일때(두번째 구독)은 purple 을 제외하고 대문자로 바꾸어 리턴 ( BLUE, GREEN, ORANGE, purple )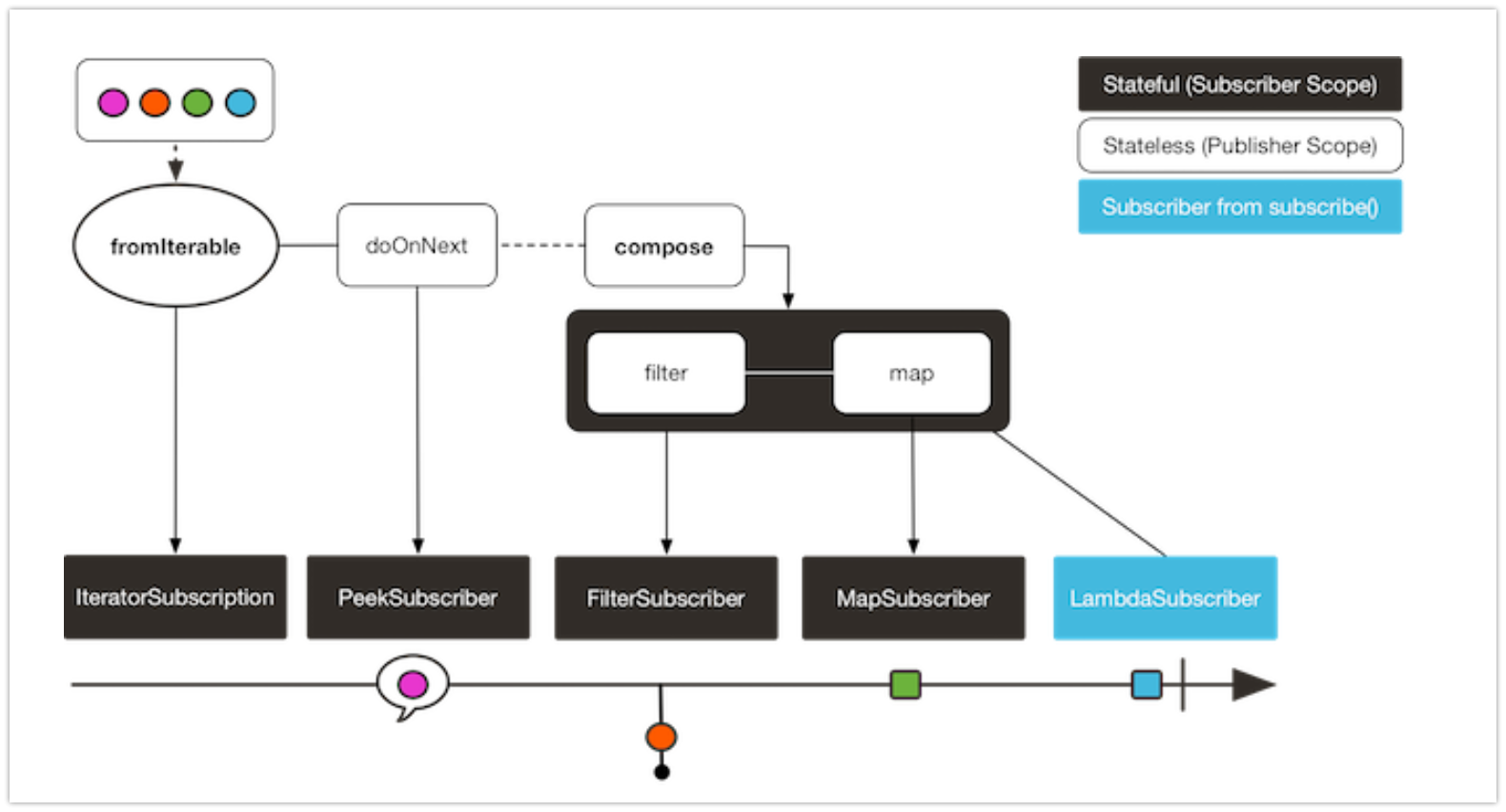
transformDeferredContextual()
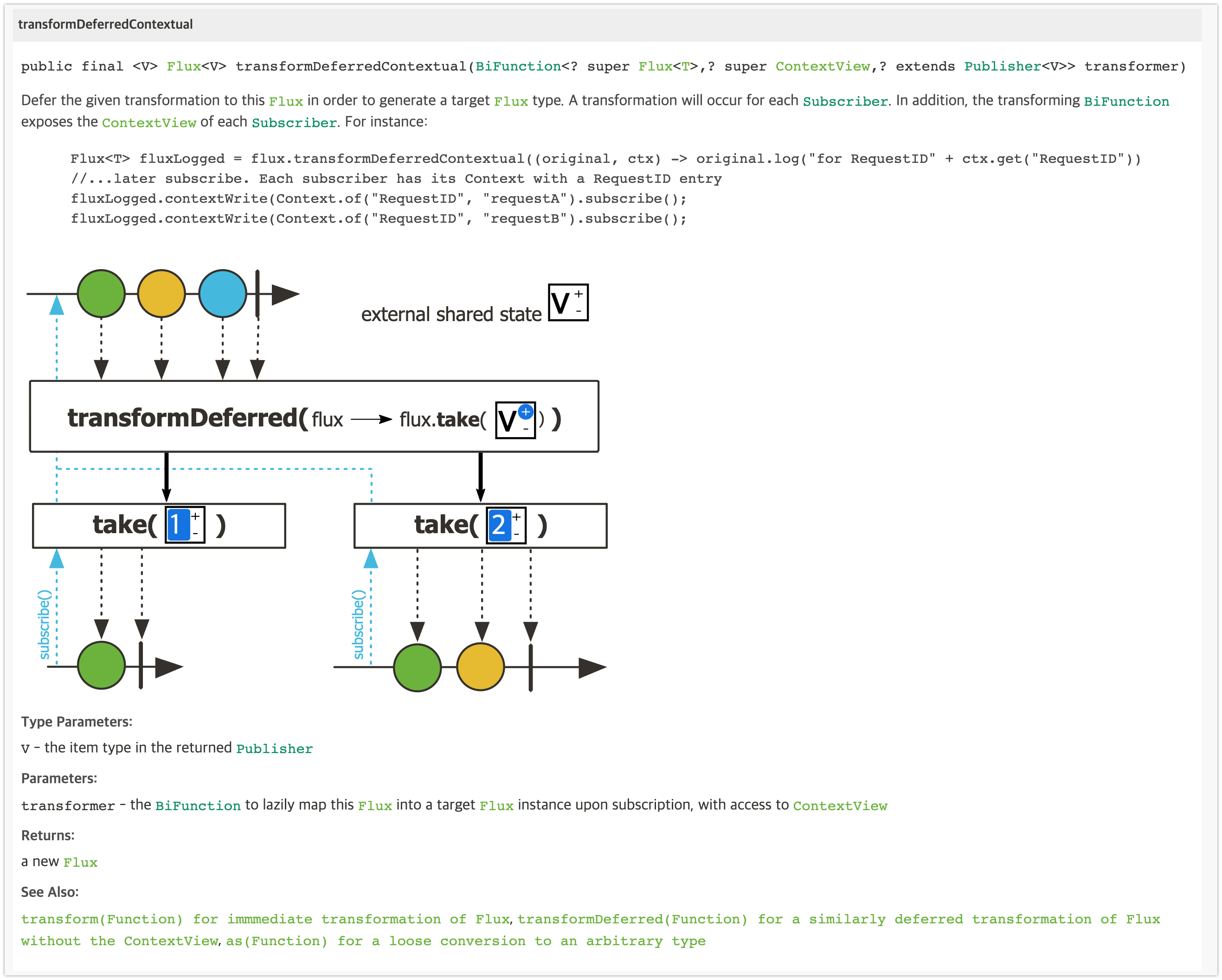
Mono.java 의 contextWrite Operator
... public final Mono<T> contextWrite(Function<Context, Context> contextModifier) { return onAssembly(new MonoContextWrite<>(this, contextModifier)); } ...contextWrite() Operator의 파라미터를 Function 타입의 함수형 인터페이스인데,
람다 표현식으로 표현할 경우 람다 파라미터 타입이 Context이고, 리턴 값도 Context이다.
Mono.java 의 deferContextual
... public static <T> Mono<T> deferContextual(Function<ContextView, ? extends Mono<? extends T>> contextualMonoFactory) { return onAssembly(new MonoDeferContextual<>(contextualMonoFactory)); } ...Reactor 에서는 Operator 체인상의 서로 다른 스레드들이 Context 의 저장된 데이터에 손쉽게 접근할 수 있습니다.
context.put() 을 통해 Context 에 데이터를 쓴 후에 매번 불변 immutable 객체를 다음 contextWrite() operator 로 전달함으로써 스레드 안정성을 보장합니다.
기억하세요
01. Context 는 일반적으로 어떠한 상황에서 그 상황을 처리하기 위해 필요한 정보를 의미한다
02. Reactor 에서의 Context
- Operator 체인에 전파되는 키와 값 형태의 저장소이다.
- Subscriber 와 매핑되어 구독이 발생할 때마다 해당 구독과 연결된 하나의 Context 가 생긴다.
- contextWrite() Operator 를 사용해서 Context 에 데이터 쓰기 작업을 할 수 있다
- deferContextual() Operator 를 사용해서 원본 데이터 소스 레벨에서 Context 의 데이터를 읽을 수 있다.
- 구독이 발생할 때 Context 가 생기므로
- transformDeferredContextual() Operator 를 사용해서 Operator 체인의 중간에서 Context 데이터를 읽을 수 있다.
2 자주 사용되는 Context 관련 API
Context API 설명 put(key, value) key/value 형태로 Context에 값을 쓴다. Context에 하나의 데이터를 쓰는 API of(key1, value2, key2, value2, ...) key/value 형태로 Context에 여러 개의 값을 쓴다. 한번의 API 호출로 여러개의 데이터를 Context에 쓸수 있는데, 최대 5개의 데이터를 파라미터로 입력할 수 있다.
6개 이상의 데이터를 쓰기 위해서는 아래의 putAll()을 쓰면된다.putAll(ContextView) 현재 Context와 파라미터로 입력된 ContextView를 merge 한다. Context의 데이터와 파라미터로 입력된 ContextView의 데이터를 합친 후, 새로운 Context를 생성한다. delete(key) Context에서 key에 해당하는 value를 삭제한다. key에 해당되는 데이터를 삭제한다. public static void main(String[] args) throws InterruptedException { final String key1 = "company"; final String key2 = "firstName"; final String key3 = "lastName"; Mono .deferContextual(ctx -> Mono.just(ctx.get(key1) + ", " + ctx.get(key2) + " " + ctx.get(key3)) ) .doOnNext(data -> log.info("just doOnNext data:{}", data)) .publishOn(Schedulers.parallel()) .contextWrite(context -> context.putAll(Context.of(key2, "Steve", key3, "Jobs").readOnly()) ) .contextWrite(context -> context.put(key1, "Apple")) .subscribe(data -> log.info("# onNext: {}" , data)) ; Thread.sleep(100L); } // result > Task :Example11_3.main() 14:55:18.873 [main] DEBUG- Using Slf4j logging framework 14:55:18.891 [main] INFO - just doOnNext data:Apple, Steve Jobs 14:55:18.895 [parallel-1] INFO - # onNext: Apple, Steve Jobs01. deferContextual() 을 사용하였으므로, emit 이 구독 시점으로 미뤄집니다
.deferContextual(ctx -> Mono.just(ctx.get(key1) + ", " + ctx.get(key2) + " " + ctx.get(key3)))
02. key2~3, key 1 을 contextWrite 합니다.
.contextWrite(context -> context.putAll(Context.of(key2, "Steve", key3, "Jobs").readOnly()))
.contextWrite(context -> context.put(key1, "Apple"))03. doOnNext 를 통해 emit 된 데이터를 확인합니다.
.doOnNext(data -> log.info("just doOnNext data:{}", data))
14:55:18.891 [main] INFO - just doOnNext data:Apple, Steve Jobs
04. subscribe onNext 의해 구독된 데이터를 출력합니다.
.subscribe(data -> log.info("# onNext: {}" , data))
14:55:18.895 [parallel-1] INFO - # onNext: Apple, Steve Jobs
Conxtext.of()
여러개의 데이터를 context 에 쓴다(변환한다?)
static Context of(Object key1, Object value1, Object key2, Object value2) { return new Context2(key1, value1, key2, value2); } static Context of(Object key1, Object value1, Object key2, Object value2, Object key3, Object value3) { return new Context3(key1, value1, key2, value2, key3, value3); }putAll()
input parameter type : ContextView
return type : newContext
여러개의 데이터를 context 에 쓸 때 사용. 동작방식은 입력된 context 를 현재의 context 에 합쳐 새로운 context 를 생성한다.
default Context putAll(ContextView other) { ... return newContext; }readOnly()
context -> Contextview 로 변환해 줍니다.
Context.of() 는 context 를 리턴하는데, putAll 에 ContextView 를 parameter 로 넘겨야 합니다. 그래서 readOnly() 를 사용했습니다
// Switch to the {@link ContextView} interface, which only allows reading from the context. default ContextView readOnly() { return this; }ContextView 관련 API
Context에 저장된 데이터를 읽으려면 ContextView API를 사용해야 합니다
map 사용과 유사합니다.
ContextView API 설명 get(key) ContextView에서 key에 해당하는 value를 반환한다. getOrEmpty(key) ContextView에서 key에 해당하는 value를 Optional로 래핑해서 반환한다. getOrDefault(key, default value) ContextView에서 key에 해당하는 value를 가져온다.
key에 해당하는 value가 없으면 default value를 가져온다.hasKey(key) ContextView에서 특정 key가 존재하는지를 확인한다. isEmpty() Context가 비어있는지 확인한다. size() Context 내에 있는 key/value의 개수를 반환한다. getOrEmpty, getOrDefault 사용 예시
public static void main(String[] args) throws InterruptedException { final String key1 = "company"; final String key2 = "firstName"; final String key3 = "lastName"; Mono .deferContextual(ctx -> Mono.just(ctx.get(key1) + ", " + ctx.getOrEmpty(key2).orElse("no firstName") + " " + ctx.getOrDefault(key3, "no lastName")) ) .publishOn(Schedulers.parallel()) .contextWrite(context -> context.put(key1, "Apple")) .subscribe(data -> log.info("# onNext: {}" , data)); Thread.sleep(100L); } // result > Task :Example11_4.main() 15:40:35.490 [main] DEBUG- Using Slf4j logging framework 15:40:35.514 [parallel-1] INFO - # onNext: Apple, no firstName no lastName기억하세요
01. Context 에 데이터 쓰기 위해서는 Context API 를 사용해야 한다
02. Context 에서 데이터를 읽기 위해서는 ContextView API 를 사용해야 한다.
3 Context의 특징
주의해야할 Context 의 특징
- 01. Context 는 구독이 발생할 때마다 하나의 Context 가 해당 구독에 연결된다
key1 에 2번 저장(overwrite) 하고, subscribe 는 2개일 때 예제
public static void main(String[] args) throws InterruptedException { final String key1 = "company"; Mono<String> mono = Mono.deferContextual(ctx -> Mono.just("Company: " + " " + ctx.get(key1)) ) .publishOn(Schedulers.parallel()); mono.contextWrite(context -> context.put(key1, "Apple")) .subscribe(data -> log.info("# subscribe1 onNext: {}", data)); mono.contextWrite(context -> context.put(key1, "Microsoft")) .subscribe(data -> log.info("# subscribe2 onNext: {}", data)); Thread.sleep(100L); } // result > Task :Example11_5.main() 16:05:57.432 [main] DEBUG- Using Slf4j logging framework 16:05:57.456 [parallel-1] INFO - # subscribe1 onNext: Company: Apple 16:05:57.456 [parallel-2] INFO - # subscribe2 onNext: Company: Microsoft01. 구독이 발생하기 전에 context key1 : Apple write & 이 후 # subscribe1 onNext 에서 data : Apple 출력
mono.contextWrite(context -> context.put(key1, "Apple"))
.subscribe(data -> log.info("# subscribe1 onNext: {}", data));16:05:57.456 [parallel-1] INFO - # subscribe1 onNext: Company: Apple
02. 2nd 구독이 발생하기 전에 key1 : Microsoft 로 overwrite 함. 이후 #subscriber2 onNext 에서 data Microsoft 출력
mono.contextWrite(context -> context.put(key1, "Microsoft"))
.subscribe(data -> log.info("# subscribe2 onNext: {}", data));16:05:57.456 [parallel-2] INFO - # subscribe2 onNext: Company: Microsoft
구독이 2개이면, 같은 key1 에 저장해도 구독에서 저장한 값을 가져온다
주의해야할 Context 의 특징
- 02. Context 는 Operator 체인의 아래에서 위로 전파된다
- 03. 동일한 키에 대한 값을 중복해서 저장하면, Operator 체인에서 가장 위쪽에 위치한 contextWrite() 이 저장한 값으로 덮어쓴다
Example 11_6 : Context 는 Operator 체인의 아래에서 위로 전파되는 예제
public static void main(String[] args) throws InterruptedException { String key1 = "company"; String key2 = "name"; Mono .deferContextual(ctx -> Mono.just(ctx.get(key1)) ) .publishOn(Schedulers.parallel()) .contextWrite(context -> context.put(key2, "Bill")) .transformDeferredContextual((mono, ctx) -> mono.map(data -> data + ", " + ctx.getOrDefault(key2, "Steve")) ) .contextWrite(context -> context.put(key1, "Apple")) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(100L); } > Task :Example11_6.main() 16:16:13.440 [main] DEBUG- Using Slf4j logging framework 16:16:13.465 [parallel-1] INFO - # onNext: Apple, Steve01. key1 : Apple 을 write 한다
.contextWrite(context -> context.put(key1, "Apple"))
02. deferContextual 에서 위게서 기록한 key1 : Apple 을 just 연산자로 emit 합니다.
.deferContextual(ctx -> Mono.just(ctx.get(key1)))
03. transformDeffered 사용하여 data 에 key2 를 읽어 오거나 default Steve 를 적용하여 더해준다
data 에 들어 있는 값 key1 : Apple
getOrDefault(key2, "Steve") : 위에서 key2 Bill 을 저장했기 때문에 Bill 이 들어갔을 것으로 예상했으나, Steve 가 적용됩니다.
→ Context 의 경우 Operator 체인상의 아래에서 위로 전파되는 특징이 있기 때문입니다.
.transformDeferredContextual((mono, ctx) -> mono.map(data -> data + ", " + ctx.getOrDefault(key2, "Steve")))
04. key2 : Bill 을 context key2 : Bill 을 저장합니다. 하지만, emit 하지 않으므로, 결과에 영향을 미치지 않습니다.
.contextWrite(context -> context.put(key2, "Bill"))
따라서 일반적으로 모든 Operator 에서 Context 에 저장된 데이터를 읽을 수 있도록 contextWrite() 을 Operator 체인의 맨 마지막에 둡니다.
주의해야할 Context 의 특징
- 05. Inner Sequence 내부에서는 외부 Context 에 저장된 데이터를 읽을 수 있다.
- 06. Inner Sequence 외부에서는 Inner Sequence 내부 Context 에 저장된 데이터를 읽을 수 없다.
Example 11_7 : 외부 Context 에 저장된 데이터를 읽을 수 없는 예제
public static void main(String[] args) throws InterruptedException { String key1 = "company"; Mono .just("Steve") // .transformDeferredContextual((stringMono, ctx) -> // ctx.get("role")) .flatMap(name -> Mono.deferContextual(ctx -> Mono .just(ctx.get(key1) + ", " + name) .transformDeferredContextual((mono, innerCtx) -> mono.map(data -> data + ", " + innerCtx.get("role")) ) .contextWrite(context -> context.put("role", "CEO")) ) ) .publishOn(Schedulers.parallel()) .contextWrite(context -> context.put(key1, "Apple")) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(100L); } // result > Task :Example11_7.main() 16:59:17.832 [main] DEBUG- Using Slf4j logging framework 16:59:17.913 [parallel-1] INFO - # onNext: Apple, Steve, CEO // result #2 line 5~6 주석을 풀 경우 Caused by: java.util.NoSuchElementException: Context does not contain key: role01 .flatMap() 내부에서는 외부에 저장된 key1 : Apple 을 읽을 수 있음
.just(ctx.get(key1) + ", " + name)
02 .flatMap() 외부에서는 flatMap 스레드에서 저장된 role: CEO 를 읽을 수 없음
.transformDeferredContextual((stringMono, ctx) -> ctx.get("role"))
Caused by: java.util.NoSuchElementException: Context does not contain key: role
public class Example11_8 { public static final String HEADER_AUTH_TOKEN = "authToken"; public static void main(String[] args) { Mono<String> mono = postBook(Mono.just( new Book("abcd-1111-3533-2809" , "Reactor's Bible" ,"Kevin")) ) .contextWrite(Context.of(HEADER_AUTH_TOKEN, "eyJhbGciOi")); mono.subscribe(data -> log.info("# onNext: {}", data)); } private static Mono<String> postBook(Mono<Book> book) { return Mono .zip(book, Mono .deferContextual(ctx -> Mono.just(ctx.get(HEADER_AUTH_TOKEN))) ) .flatMap(tuple -> { String response = "POST the book(" + tuple.getT1().getBookName() + "," + tuple.getT1().getAuthor() + ") with token: " + tuple.getT2(); return Mono.just(response); // HTTP POST 전송을 했다고 가정 }); } } @AllArgsConstructor @Data class Book { private String isbn; private String bookName; private String author; } // result > Task :Example11_8.main() 17:08:32.252 [main] DEBUG- Using Slf4j logging framework 17:08:32.393 [main] INFO - # onNext: POST the book(Reactor's Bible,Kevin) with token: eyJhbGciOi01. main 에서 new Book 을 emit 하고, 그 데이터로 postBook 메소드를 호출
postBook(Mono.just( new Book("abcd-1111-3533-2809", "Reactor's Bible","Kevin") ))
02. postBook 에서 zip() 연산자를 사용하여, parameter 로 전달받은 new Book Mono 와 deferContextual 로 HEADER_AUTH_TOKEN 을 읽어오는 Mono 하나의 Mono 로 합칩니다.
.zip(book, Mono.deferContextual(ctx -> Mono.just(ctx.get(HEADER_AUTH_TOKEN))))
HEADER_AUTH_TOKEN 는 main 의 마지막 operator 에서 기록되었지만, context 는 아래에서 위로 전파되기 때문에
postBooK 메서드의 zip() 연산자에서 사용할 수 있습니다.
03. .flatMap 에서 데이터를 string 연산하여 emit 합니다.
.flatMap(tuple -> {
String response = "POST the book(" + tuple.getT1().getBookName() +
"," + tuple.getT1().getAuthor() + ") with token: " +
tuple.getT2();
return Mono.just(response); // HTTP POST 전송을 했다고 가정
});Context 는 인증 정보 같은 직교성(독립성)을 가지는 정보를 전송하는 데 적합하다는 사실을 기억하기 바랍니다.
zip()
Reactor가 zip method를 사용하면 두 개의 소스를 병합할 수 있습니다. 다양한 형태의 zip 메소드들을 지원하고 있으며, 모든 zip 메소드는 '주어진 입력 소스를 병합하는' 동일한 역할을 합니다. 아래의 그림에서 볼 수 있듯이, zip 메소드는 여러 Source나 Provider를 받습니다.
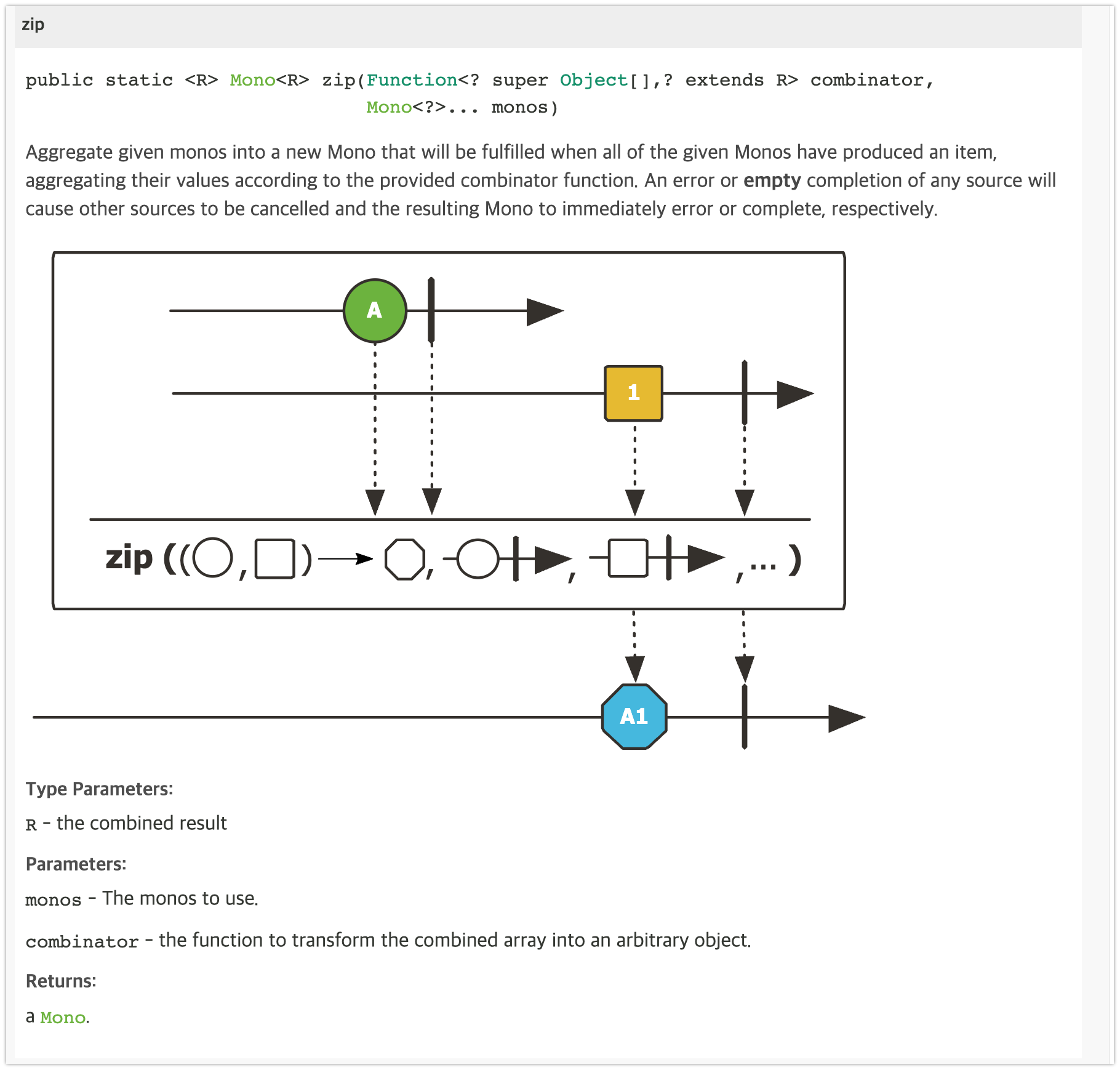
Mono zip() mable diagram 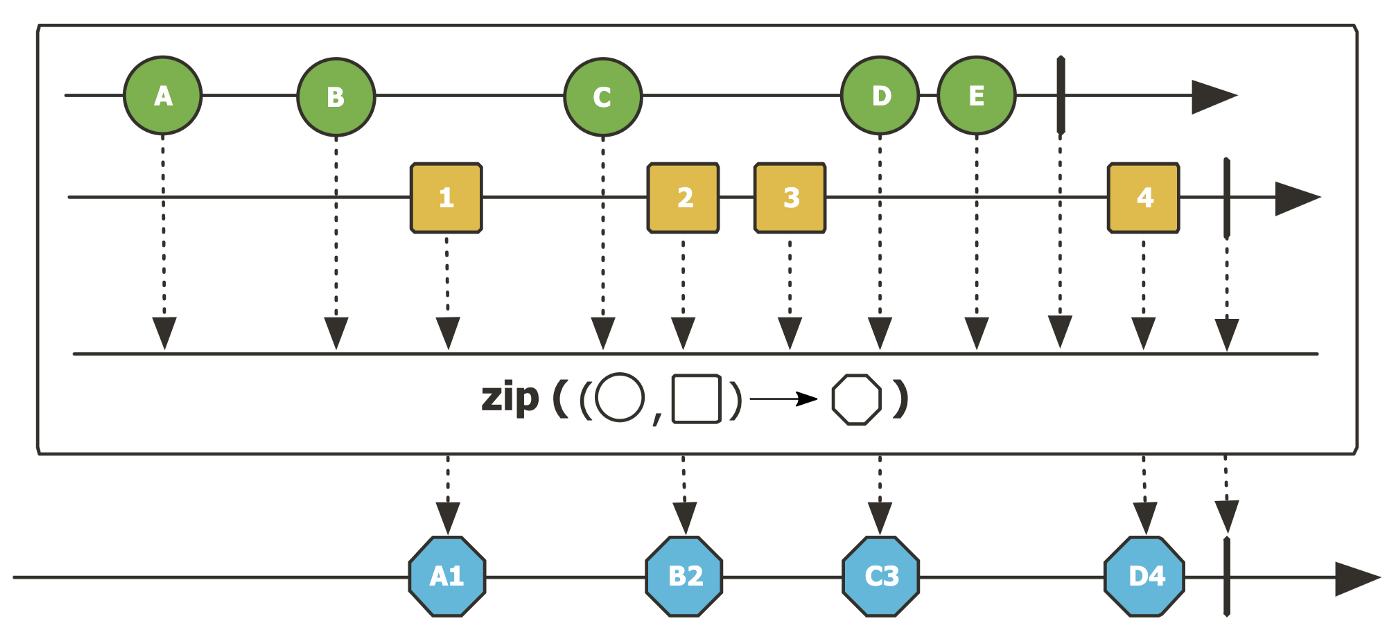
그림의 표현된 내용을 보면, 첫 번째 소스는 A부터 E까지의 다섯 개의 소스(🟢)를 방출하고, 두 번째 소스는 1부터4까지의 네 개의 소스 (🟥)를 방출합니다. 모든 소스는 다른 소스에서 방출되는 요소가 있을 때 방출되어 병합됩니다.
각 소스는 병합되어 하나씩 방출되어야 하기 때문에, 다른 소스에서 방출되는 요소가 없다면 대기합니다. 때문에 위의 그림에서 A1, B2, C3, D4이 출력되고 첫 번째 소스에서 방출된 E는 결합되지 않은 것을 알 수 있습니다.
기억하세요
01. Context 는 구독이 발생할 때마다 하나의 Context 가 해당 구독에 연결된다.
02. Context 는 Operator 체인의 아래에서 위로 전파된다.
03. 동일한 키에 대한 값을 중복해서 저장하면, Operator 체인상에서 가장 위쪽에 위치한 contextWrite() 이 저장한 값으로 덮어쓴다
04. Inner Sequence 내부에서는 외부 Context 에 저장된 데이터를 읽을 수 있다.
05. Inner Sequence 외부에서는 Inner Sequence 내부 Context 에 저장된 데이터를 읽을 수 없다.
06. Context 는 인증 정보 같은 직교성(독립성)을 가지는 정보를 전송하는 데 적합하다
참고
https://devfunny.tistory.com/916
[리액티브 프로그래밍] Reactor의 Context
Context the situation, events, or onformation that are related to something and that help you understand it '어떤 것을 이해하는데 도움이 될만한 관련 정보나 이벤트, 상황'로 해석된다. 즉, Context는 어떠한 상황에서 그
devfunny.tistory.com
'Spring > Webflux' 카테고리의 다른 글
13장 Testing (0) 2023.05.27 12장 Debugging (0) 2023.05.21 10장 Scheduler (0) 2023.05.07 9장 Sinks (0) 2023.05.01 8장 backpressure (0) 2023.04.23