-
1장 LLM 지도 1.1 딥러닝과 언어모델LLM/LLM을 활용한 실전 AI 애플리케이션 개발 2025. 1. 3. 08:54
목차
딥러닝(deep learning)이란 인간의 두뇌에 영감을 받아 만들어진 신경망(neural network)
데이터의 패턴을 학습하는 머신러닝(machine learning)의 한 분야다
텍스트와 이미지(비정형 데이터,unstructured data)에서도 뛰어난 패턴 인식 성능을 보여, AI 주류 모델이 됨
자연어 처리(NLP, natural language processing)
자연어 생성(NLG, natural language generating)LLM은 다음에 올 단어가 무엇일지 예측하면서 문장을 하나씩 만들어 가는 방식으로 텍스트를 생성
이렇게 다음에 올 단어를 예측하는 모델을 언어 모델(Language Model) 이라고 함
LLM 은 딥러닝 기반의 언어 모델이다.
그림 1.2 딥러닝과 언어 모델링 관점에서 주요 사건 3가지 주요 사건
1. 워드투백(word2vec) : 단어를 의미를 담아 숫자로 표현
2. 트랜스포머(transformer) 아키텍처
3. openAI가 transformer 를 활용한 GPT-1 모델공개1.1.1 데이터의 특징을 스스로 추출하는 딥러닝
2012년 ImageNet 대외에서 딥러닝 모델인 AlexNet 이 우승하며, 딥러닝이 주목 받음
딥러닝 문제 해결 방식
1. 문제의 유형(예, 자연어 처리, 이미지 처리)에 따라 일반적으로 사용되는 모델을 준비한다
2. 풀고자 하는 문제에 대한 학습 데이터를 준비한다
3. 학습 데이터를 반복적으로 모델에 입력한다
그림 1.3 머신러닝과 딥러닝의 차이 (구세대) 머신러닝 vs 딥러닝
(구세대) 머신러닝 : 특징(패턴)을 사람이 추출
딥러닝 : 특징추출+분류를 모델 스스로 함바퀴가 있고 문이 달려있고 창문이 있는등의 일반적인 특징을 사람이 입력하면, 머신러닝
모델이 스스로 알아서 추출하면 딥러닝
1.1.2 임베딩 : 딥러닝 모델이 데이터를 표현하는 방식
데이터의 의미와 특징을 포착해 숫자로 표현한 것을 임베딩(embedding)이라고 부른다
MBTI 를 이용한 임베딩 설명

그림 1.4 MBTI의 네가지 범주 
그림 1.5 MBTI 검사결과 예시 어떤 사람이 각 범주에서 1.5와 같은 점수를 받았다면
MBTI 는 INTP 가 되고, 숫자로 나타내면 [ 0.3, 0.2, 0.9, 0.2 ] 로 간단히 표현할 수 있다
어떤 사람의 성향이라는 복잡한 데이터를 단 4개의 숫자로 표현한 것이다
MBTI 를 숫자로 나타내면
나와 비슷한 사람, 나와 다른 사람이 누군지 찾고, 어떤 점이 비슷하고 다른지 따져보기 편리하다
마찬가지로, 데이터를 임베딩으로 표현하면 데이터 사이의 거리를 계산하고 관련 있는 데이터와 관련이 없는 데이터를 구분할 수 있다.
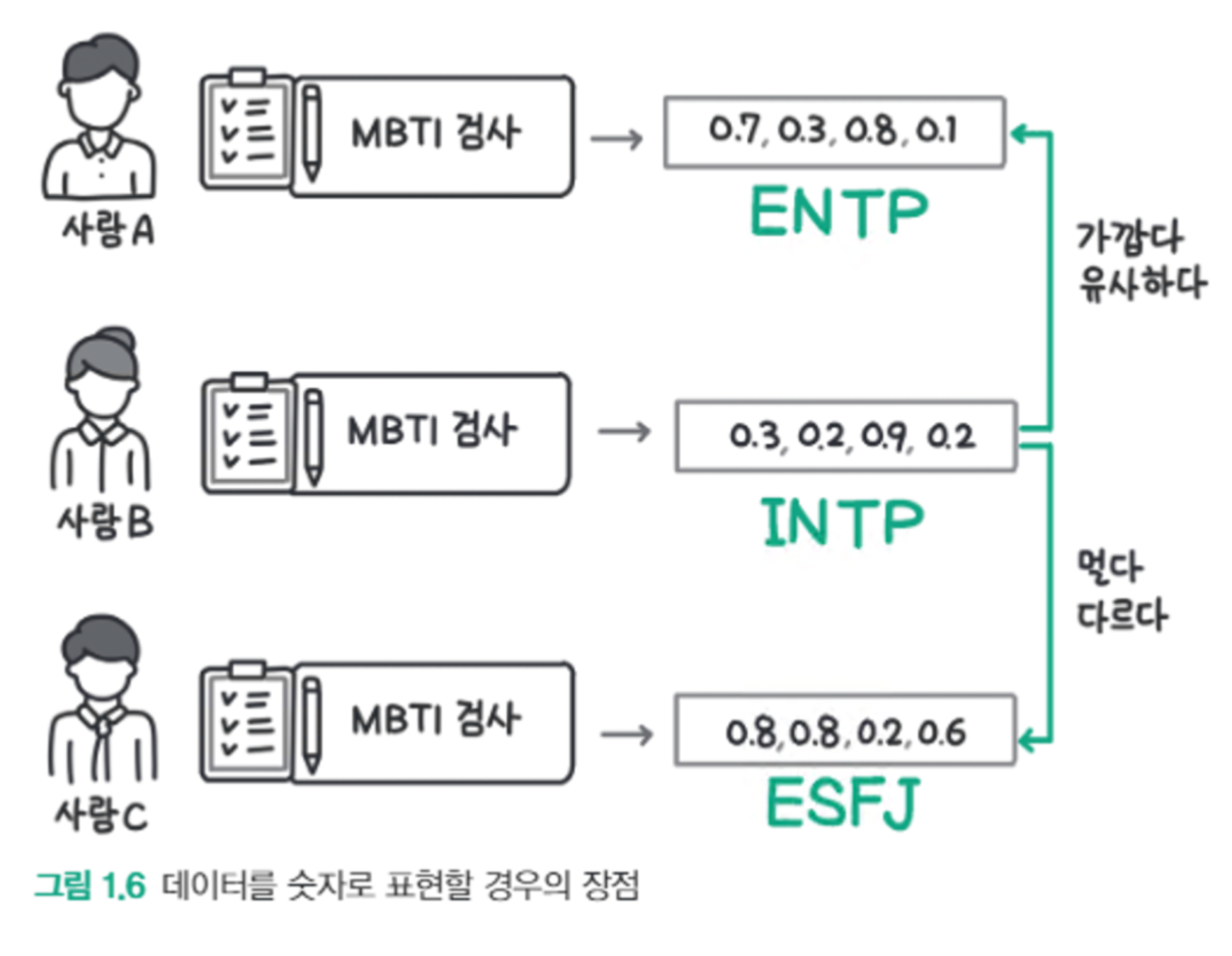
그림 1.6 데이터를 숫자로 표현할 경우의 장점 임베딩은 거리를 계산할 수 있기 때문에 다음과 같은 작업에 활용할 수 있다
- 검색 및 추천 : 검색어와 관련이 있는 상품을 추천한다
- 클러스터링 및 분류 : 유사하고 관련이 있는 데이터를 하나로 묶는다.
- 이상치(outlier) 탐지 : 나머지 데이터와 거리가 먼 데이터는 이상치로 볼 수 있다
2013년 구글에서 발표한 Efficient Estimation of Word Representations in Vector Space 논문에서 워드투벡(Word2Vec)이라는 모델을 통해 단어를 임베딩으로 변환하는 방법을 소개했다
단어 임베딩 word embedding

그림 1.7 워드투벡을 활용해 단어를 임베딩으로 표현하기 MBTI 는 사람이 설계했기 때문에 각 숫자가 어떤 의미인지 정확히 알 수 있었지만,
단어 임베딩에서는 0.1 0.7과 같은 숫자가 어떤 의미인지 알기 어렵다
딥러닝 모델이 데이터에서 알아서 특징을 추출하기에 사람이 그 의미를 하나하나 파악하기 힘들다.

표 1.1 MBTI 검사의 숫자 표현과 임베딩 모델 숫자 표현의 공통저모가 차이점 딥러닝 모델은 데이터를 통해 학습하는 과정에서, 그 데이터를 가장 잘 이해할 수 있는 방식을 함께 배운다
그렇게 데이터의 의미를 숫자로 표현한 것이 바로 임베딩이다
※ 임베딩의 설명이 더 필요하여, AI 에게 추가 질의하였다
컴퓨터는 숫자만 처리할 수 있기에, 딥러닝 모델은 데이터를 숫자의 집합으로 표현하는 임베딩이 필요합니다.
Embedding 이란
데이터들을 특정한 방식으로 변환하여 데이터의 특징을 추출하고,
이를 숫자 벡터로 표현하는 것을 임베딩이라고 합니다.
"사과"와 "바나나"는 "컴퓨터"보다 더 가까운 값을 가질 수 있도록 임베딩을 설계합니다.* embed [ ɪmˈbed ] : 어떤 대상을 다른 공간에 삽입한다
수학: 수학에서는 한 집합을 다른 집합의 부분집합으로 만들어 넣는 것을 의미합니다.
언어: 어떤 단어나 문장을 다른 문맥 속에 넣어 새로운 의미를 부여하는 것을 의미합니다.
1.1.3 언어 모델링: 딥러닝 모델의 언어 학습법
언어 모델링이란, 모델이 입력받은 텍스트의 다음 단어를 예측해 텍스트를 생성하는 방식을 말한다
다음 단어를 예측하는 방식으로 훈련한 모델을 언어 모델(Language Model) 이라고 한다
대량 데이터에서 언어의 특성을 학습하는 사전 학습(pre-training)과제로 많이 사용된다.
전이 학습(Transfer learning)이란
하나의 문제를 해결하는 과정에서 얻은 지식과 정보를 다른 문제를 풀 때 사용하는 방식
전이 학습에서 대량의 데이터로 모델을 학습 시키는 사전학습과
특정한 문제를 해결하기 위한 데이터로 추가학습 하는 것을 미세 조정(fine-tuning)의 두 단계로 나눠 학습을 진행한다.
사전학습(pre-training) 예
대량의 이미지넷 데이터셋을 통해 동물을 분류(예, 새, 고양이, 개 등)하도록 학습한다
추가학습, 미세조정(fine-tunning) 성능효과 예
유방암이 양성인지 악성인지 분류하는 새로운 문제를 풀고자 할 때, 유방암 데이터만으로 학습한 모델보다,
사전 학습 모델의 일부를 가져와 활용했을 때 일반적으로 성능이 더 높다

그림 1.8 이미지 인식 분야의 전이 학습 Transfer Learning 
그림 1.9 기존의 지도학습(Supervised Learning) 방식과 전이학습(Transfer Learning) 방식의 차이 1.9(a) 가 기존의 지도 학습(supervised learning) 방식으로, 각각의 데이터셋으로 별도의 모델을 학습시켰다
1.9(b)는 전이 학습(transfer learning)로, 모델 본체 부분은 대규모 데이터셋인 이미지넷으로 학습한 모델에서 가져오고,
분류를 수행하는 헤드부분은 각 용도별 데이터셋으로 추가학습한다.
이 때 헤드를 추가 학습하는 과정이 사전 학습에 비해 적은 양의 학습 데이터를 사용한다는 의미에서 미세 조정(fine-tuning)이라고 부른다
자연어 처리 분야에서는 2018년 fast.ai 의 제레미 하워드 Jeremy Howard 와 세바스찬 루더 Sbastian Ruder 가
다음 단어를 예측하는 언어 모델링 방식으로 사전 학습을 수행했을 때, 훨씬 적은 레이블 데이터로도 성능이 뛰어나다는 사실을 발견했다 ( Universal Language Model Fine-Tuning for Text Classification)

그림 1.10 언어 모델링을 통한 학습이 분류 성능에 미치는 영향 그림 1.10(a) 에서 다음 단어를 예측하는 방식으로 언어 모델을 사전 학습하고 나서,
그림 1.10(b) 와 같이 (영화분류) 다운스트림 과제의 데이터셋으로 언어 모델 미세 조정을 수행하고,
그림 1.10(c) 와 같이 텍스트 분류 미세 조정을 했을 때, 바로 텍스트 분류 모델로 학습 시켰을 때 보다 성능이 높았다.
제레미 하워드와 세바스찬 루더는, 당시 많이 활용되던 순환신경망(RNN, Recurrent Neural Network)에서 언어 모델링이 사전 학습 과제로 적합하다는 사실을 확인했다
그후, 2017년 구글의 아쉬쉬 바스와니(Ashish Vaswani)가 발표한 Attention is All you need 논문에서 트랜스포머 아키텍처를 활용할 모델이 처음 등장하였으며,
OpenAI 의 GPT-1 의 논문 Improving Language Uderstanding by Generative Pre-Training 이 나오는등 ,
자연어 처리분야에서 가장 대표적인 사전 학습 방법으로 자리 잡았다
Keyword
Machine Learning vs Deep Learning
Deep Learning 은 Machine Learning 의 한 종류로, 인공 신경망을 이용하여, 더욱 복잡한 문제를 해결
Deep Learning :
- 인공신경망을 기반으로 모델에 학습데이터를 반복적으로 입력하여 패턴을 인식
- 문제를 풀기위한 특징추출 분류를 모델이 알아서 함
word2vec → transformer → Gpt-1
word2vec : 단어를 의미를 담아 숫자로 표현
transformer : 어텐션 메커니즘 사용, 인코더와 디코더로 나뉨, 병렬처리 가능, 포지셔널 인코딩
Embedding : 데이터의 의미와 특징을 포착해 숫자로 표현, 집합과 벡터 사용
Transfer Learning : 하나의 문제를 해결과정에서 얻은 지식과 정보를 다른 문제 풀 때 사용하는 방식
pre-training : 대량의 데이터로 모델을 학습(예 이지미넷 데이터로 이미지 학습)
fine-tuning : 특정 데이터로 추가학습(예: 유방암 데이터로 추가 학습)
책 출처 : https://ridibooks.com/books/3649000042
LLM을 활용한 실전 AI 애플리케이션 개발
LLM을 활용한 실전 AI 애플리케이션 개발 작품소개: 트랜스포머 아키텍처부터 RAG 개발, 모델 학습, 배포, 최적화, 운영까지 라마인덱스와 LLM을 활용한 AI 애플리케이션 개발의 모든 것이 책에서는
ridibooks.com
'LLM > LLM을 활용한 실전 AI 애플리케이션 개발' 카테고리의 다른 글
2.5 인코더 (0) 2025.01.10 2.3 어텐션 이해하기 (0) 2025.01.10 2장 LLM의 중추, 트랜스포머 아키텍처 살펴보기 (1) 2025.01.10 1.2 언어 모델이 챗GPT가 되기까지 (1) 2025.01.09 책 - LLM을 활용한 실전 AI 애플리케이션 개발 (0) 2025.01.03